
後量子密碼學中的程式碼優化
原文:https://mirror.xyz/privacy-scaling-explorations.eth/BKI3tyauHIiUCYHgma-EHeSRXNTNDtLUQV9VNGQWLUg
作者:Miha Stopar (PSE)
譯者:Kurt Pan
毋庸置疑,基於格的密碼學目前是後量子密碼學中最有前景的分支之一。它不僅效率極高且用途廣泛,同時也是目前唯一已知能實現全同態加密的技術。
基於格的密碼學之所以如此之快,其中一個原因在於它可以重度向量化。這與基於同源映射的密碼學形成鮮明對比,後者提供的並行處理機會要少得多。在本文中,我將簡要比較這兩種密碼學範式在向量化方面的潛力。當然,這兩個分支僅是後量子密碼學更廣泛領域中的一部分。
向量化
向量化是指利用單一指令多資料 (SIMD) 技術,同時執行多個操作的過程。這是一種利用現代處理器指令,如 SSE (Streaming SIMD Extensions)、AVX (Advanced Vector Extensions) 及其更新版本 AVX-512,加速運算的強大方式。
但這究竟是什麼意思呢?
假設我們想要對下列32個位元組進行異或運算:
Input: 11001010 10101100 00011011 ...
Key : 10110110 01100100 11100011 ...
---------------------------------
Output: 01111100 11001000 11111000 ...
相比逐個位元組進行32次操作,AVX 能夠一次執行32個位元組的異或運算:
__m256i data = _mm256_loadu_si256(input)
__m256i key = _mm256_loadu_si256(key)
__m256i hash = _mm256_xor_si256(data, key)
首先,AVX2 暫存器利用輸入數據載入32個位元組(256 位元)進入一個256位元的暫存器。接著,它將32個位元組的密鑰載入另一個暫存器。最後,它逐元素地對數據與密鑰進行按位異或。然而在這裡,32個位元組在一條指令中就被處理了!
基於格的密碼學
基於格的密碼學核心在於矩陣向量乘法。例如,讓我們考慮一個二維格 L,其基底為 {v₁, v₂}。格元素是形如 a₁·v₁ + a₂·v₂ 的向量,其中 a₁, a₂ ∈ ℤ。如果我們構造一個矩陣 M,使得 v₁ 和 v₂ 成為該矩陣的兩個欄位,那麼將矩陣 M 與向量 (a₁, a₂)ᵀ 相乘便得到一個格元素。
在格密碼的核心,是矩陣向量乘法。例如,讓我們考慮一個二維格 ,其基為 . 格元素是形如 的向量,其中 . 如果我們構造一個矩陣 使得 與 成為此矩陣的兩列,則將 與向量 相乘,就會得到一個格元素。
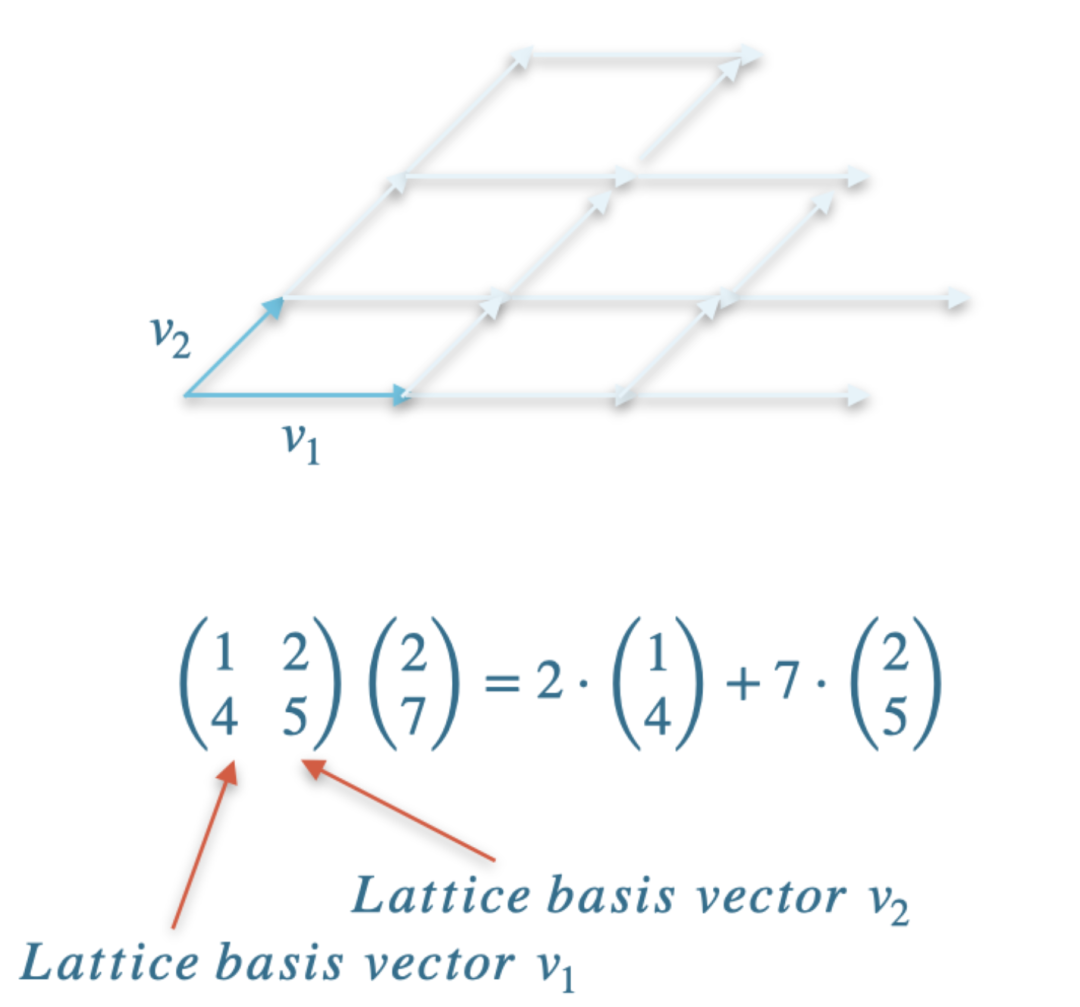
矩陣乘法示意圖
出於效能考量,格密碼依賴多項式環而非普通向量。我不會討論細節,但考慮以下例子。
上面的矩陣向量乘法實際上相當於在環 中兩個多項式的乘法。
注意在這個環中,有 。在實際應用中, 通常是 2 的冪,例如 。
因此,當對多項式 與 進行乘法,並考慮 ,我們就得到了與上方矩陣向量乘法相同的結果。
具有這種形式的矩陣有兩個好處:一是所需存儲空間較少(對於一個 3×3 矩陣僅需 3 個元素),二是我們可以使用數論變換 (NTT) 演算法進行多項式乘法,而不必直接進行矩陣向量乘法。使用 NTT 時,我們是將多項式的值相乘,而不是直接處理多項式係數,從而將運算複雜度從 降低到 。
https://en.wikipedia.org/wiki/Discrete_Fourier_transform_over_a_ring
這意味著我們不是直接計算多項式的乘積
為
而是應用 NTT 來計算 和 的值。這使我們僅需進行 次逐點乘法,大幅提升運算效率:
如此一來,我們便得到了在 處 的值。為了恢復 的係數,需應用逆 NTT。在下一節中,我們將探討向量化是如何進一步加速此類點運算的。
格與向量化
那麼,為什麼基於格的密碼學特別適合向量化呢?
通常格密碼處理的是多項式,這些多項式屬於 或者 。當 時,每個多項式有 64 個係數,例如:
現在,若要計算 ,你需要計算
這很容易向量化:我們需要將 與 載入一個 AVX 暫存器。假設該暫存器有 32 個槽位,每個槽位長 16 位元。如果係數小於 16 位元,我們可以使用兩個暫存器來表示一個多項式。藉由單一指令,我們即可計算出前 32 個係數的和:
a₁ | a₂ | ... | a₃₁
b₁ | b₂ | ... | b₃₁
-> a₁ + b₁ | a₂ + b₂ | ... | a₃₁ + b₃₁
在第二條指令中,我們計算接下來 32 個係數的和:
a₃₂ | a₃₃ | ... | a₆₃
b₃₂ | b₃₃ | ... | b₆₃
-> a₃₂ + b₃₂ | a₃₃ + b₃₃ | ... | a₆₃ + b₆₃
許多基於格的方案大量依賴矩陣向量乘法,與上述方法類似,這些運算可以自然地使用向量化指令來表達。回到 NTT,我們看到這兩個多項式可通過向量化,在僅兩條指令中(一次進行 32 次點乘法)的配合下,再加上 NTT 與其逆運算,高效地相乘。
同源與向量化
相反地,對基於同源映射的方案進行向量化顯得相當具挑戰性。同源映射是一個椭圓曲線之間的同態映射,而基於同源映射的密碼學則依賴於假設在兩個給定的曲線之間找到一個同源映射是困難的。
在同源密碼中,並不存在具有 64 或 128 個元素的結構能夠直接進行向量化。該類密碼學所採用的優化手段與傳統椭圓曲線密碼學相似。但請注意,基於離散對數問題的傳統椭圓曲線密碼學並不具有量子安全性,而同源密碼被認為具有量子安全性:目前尚未有已知的量子演算法能夠高效地找到兩個椭圓曲線之間的同源映射。
我們來看看椭圓曲線密碼學中所使用的一些優化手段:
選擇質數 使得在有限域 中的算術運算能夠高效執行
蒙哥馬利歸約:能夠在不進行昂貴除法運算的情況下,高效地計算模歸約
蒙哥馬利求逆:在搭配蒙哥馬利乘法使用時,完全避免使用除法
使用蒙哥馬利或愛德華曲線:可實現高效算術運算
沙米爾技巧:能夠同時計算 ,從而減少運算次數
值得注意的是,其中某些優化手段——例如蒙哥馬利歸約與蒙哥馬利乘法——同樣適用於格密碼。
來看一個簡單的例子,以說明選擇適合的質數 以實現高效有限域運算的重要性。若我們選擇 (即 能被 4 整除),則計算平方根變得相當簡單:找 的平方根,只需計算
根據費馬小定理,我們有 ,亦即:
橢圓曲線運算可以向量化,但其程度不如基於格的運算。舉例來說,一個例子是以基數 表示法處理域元素:
其中對於 ,有 。
https://orbilu.uni.lu/bitstream/10993/48810/1/SAC2020.pdf
然而,在 SIMD 優化中,通道數的數量扮演著關鍵角色。在格密碼中,使用 64 或 128 個通道非常簡單,這大大提升了並行處理能力。相比之下,上述例子僅利用了 9 個通道,從而限制了 SIMD 優化的潛力。
結論
基於格的密碼學目前處於後量子密碼學技術發展的最前沿,而其卓越的效能正是其顯著優勢之一。近年來,基於同源映射的密碼學卻有些不公地獲得了被破解的名聲。這是由於 Castryck-Decru 攻擊,但該攻擊僅適用於那些暴露了有關同源映射額外資訊(即兩個點的像)的方案。
https://eprint.iacr.org/2022/975
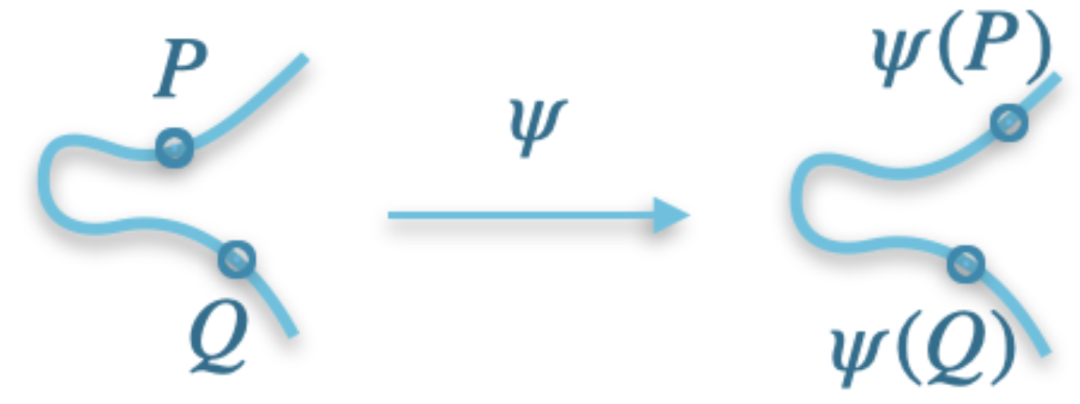
給定同源映射 下兩個點的像,就可以計算其他點的像。為此,採用了 1997 年的一個顯著結果——卡尼引理。幸好,許多基於同源映射的方案並不暴露點的像。例如,SQIsign 就具有超緊湊的密鑰和簽章,其尺寸可與基於椭圓曲線的簽章方案媲美。總之,基於同源映射的密碼學在效能和通用性上不如基於格的密碼學;然而,它具有密鑰和簽章尺寸更小等優點。
https://mast.queensu.ca/~kani/papers/numgenl.pdf https://sqisign.org/
在未來幾年中,後量子密碼學哪一領域會成為主流,令人期待。我尚未深入探討基於編碼、基於多變量或基於雜湊函數的密碼學,而這些方法各自都有其優勢與挑戰。