
如何證明錯誤的陳述(一)
原文:https://blog.cryptographyengineering.com/2025/02/04/how-to-prove-false-statements-part-1/
作者:Matthew Green
譯者:Kurt Pan
(警告:這是一篇極為艱深的理論密碼學文章,且由非理論學者撰寫!)
如果你長期關注我的部落格,你應該已經了解到,我基本上有兩個主要的興趣點。一是構建「實用」的加密方案,解決現實世界中的實際問題。另一個則是對支撐這些方案(特別是它們的安全性)的理論模型產生了一種奇怪的執念。特別是,我最喜歡批判的對象之一是所謂的 隨預言機模型(random oracle model, ROM)——基本上是一種將雜湊函數進行抽象化的方式。
最近,一篇由 Khovratovich、Rothblum 和 Soukhanov 撰寫的論文吸引了我的興趣,題為《如何證明錯誤的陳述:對 Fiat-Shamir 的實用攻擊》。這真是一篇極具衝擊力的論文!它觸及了我思維中的許多敏感點:它敦促我們深入理解安全性證明的理論模型,它的標題包含了「實用」和「攻擊」這兩個詞,最重要的是,它展示了一種針對區塊鏈等系統中「零知識」(但實際上並不是零知識,稍後會解釋)證明系統的真實(儘管是極端設計的)攻擊方式。
https://eprint.iacr.org/2025/118
老實說,我仍然在努力理解自己對這一結果的「感受」。你可能覺得奇怪,我的感受為何會重要?這畢竟是科學,數學不是應該能夠說明一切嗎? 但令人擔憂的是,在這種情況下,我認為數學並不能自圓其說。事實上,這正是我認為這個結果最令人興奮的地方:我們如何思考這個問題確實很重要。(在此,我必須補充,並不是所有人都與我的看法一致。我的博士生 Aditya Hegde 曾與我激烈爭論這個問題,而且從理論上來說,他大部分時候都能說服我。因此,如果我在這篇文章中說了一些不那麼愚蠢的話,那可能要歸功於他。)
哦對了,我還應該提一下,這個問題涉及到數十億美元的資金(參見這裡)。這並不是誇張,這確實是事實。
https://defillama.com/chains/Rollup
我之前提到過,這篇文章會又長又晦澀,這是無法避免的。但我保證它會很有趣。(好吧,其實我也不能保證。)管他的,開始吧!
最簡短的背景介紹(但仍然很長)
如果你長期閱讀這個部落格,你可能已經知道,我對加密學的一個「技巧」異常著迷。這個技巧被稱為隨機預言機模型,它是密碼學歷史上最糟糕(或最棒)的發明之一。
簡單來說,密碼學常使用一種稱為 密碼雜湊函數(cryptographic hash function)的工具。這些函數接收一個(可能很長的)輸入,並輸出一個固定長度的摘要。我們希望這些函數滿足一些基本的安全性要求,例如抗碰撞性和抗原像 等等。但現實世界中的許多加密方案,為了證明它們的安全性,具體來說,我們通常假設這些雜湊函數的行為類似於隨機函數(random functions)。
如果你不確定什麼是隨機函數,你可以在這裡深入了解。你只需要相信,這是一種對雜湊函數來說非常強大且美好的要求!但這裡有一個問題:現實世界中的雜湊函數不可能是隨機函數。具體來說,像 SHA-2、SHA-3 這樣的具體雜湊函數,必然具備緊湊且高效的演算法,而真正的隨機函數則不能如此使用。事實上,一個隨機函數的最有效描述方式,基本上就是一個龐大的查找表(即輸入與輸出之間的對應關係),其大小隨輸入長度呈指數增長。這意味著這樣的函數根本無法高效計算,因為規模太龐大了。
https://blog.cryptographyengineering.com/2023/05/08/prfs-prps-and-other-fantastic-things/
所以,當我們分析某些依賴雜湊函數「必須表現得像隨機函數」的加密方案時,我們不得不做一些相當可疑的事情。這種做法異常瘋狂:首先,我們在一個人工構造的「模型」中進行分析,在這個模型裡,所有的計算方(包括誠實的參與者和攻擊者)都能夠查詢隨機函數,儘管這在現實中是不可能的。為了讓這個明顯的矛盾變得「合理」,我們把雜湊函數的邏輯封裝進一個神奇的黑盒子,這個黑盒子存在於參與者之外——所有人都只能通過查詢的方式與之交互。這個新東西,就是所謂的隨機預言機(random oracle)。
這種方法導致了一個奇怪的後果:沒有任何一方能夠知道這個「雜湊函數」的具體實現。他們根本無法知曉,因為在這個模型中,這個雜湊函數本質上是一個龐大的隨機查找表,而它的規模太大了,沒有人可以真正存儲或理解它!這看起來似乎沒什麼大不了的,但接下來你會發現,這個細節異常重要。
在現實世界中,我們顯然並沒有真正的隨機預言機。當然,我們可以設置一台特殊的伺服器,讓全世界的人都來查詢哈希值,但這根本不現實。所以,當我們真正要部署一個基於隨機預言機模型的方案時,我們不得不做一件非常糟糕的事情——「實例化」隨機預言機,也就是用一個實際的哈希函數(比如 SHA-2 或 SHA-3)來替代它。然後,大家就這樣隨意地運行這個系統,希望它的安全性證明仍然有效。
讓我再一次強調這個關鍵點:從理論上講,任何在隨機預言機模型下被證明安全的方案,一旦將隨機預言機替換為真實的雜湊函數(如 SHA-3),它的「可證安全性」將完全消失。 換句話說,這就好比你把汽車引擎的機油換成了食用油(Crisco)。你的車可能還能運行,但你已經完全失去了保證。
但、但、但(是的,我強調到結巴),失去保證並不一定意味著你的引擎會馬上壞掉! 在大多數情況下,當我們「實例化」隨機預言機時(這幾乎適用於所有現實世界中部署的協議),它們似乎都能正常運作。
(當然,我們確實見過因雜湊函數缺陷導致的加密協議崩潰,比如 這個案例),但這些問題通常是因為明顯的哈希函數漏洞,例如碰撞攻擊。這些漏洞並不是什麼神秘的「理論陷阱」,而是顯而易見的錯誤。就目前而言,如果你使用一個「足夠好」的安全雜湊函數來實例化隨機預言機,那麼一切大概率都會運行良好。)
https://blog.cryptographyengineering.com/2012/06/05/flame-certificates-collisions-oh-my/
然而,理論學者對這種草率的做法並不滿意。在 1990 年代,他們發起了一場「理論反叛」,並展示了一個令人震驚的事實:存在一些「刻意構造的」密碼方案,在隨機預言機模型下是可證安全的,但只要你用任何具體的雜湊函數來實例化它,它就會變得完全不安全!
https://blog.cryptographyengineering.com/2020/01/05/what-is-the-random-oracle-model-and-why-should-you-care-part-5/
這一發現震驚了整個密碼學界,但如果你聽過這個故事的細節,其實它並不那麼令人意外。大多數這類「反例方案」基於以下四個簡單的觀察點:
在隨機預言機模型中,你無法知道雜湊函數的具體演算法,因為它是一個隨機的巨大查找表。
在現實世界中,你顯然知道雜湊函數的演算法(比如這裡有 SHA-256 的具體代碼)。
我們可以設計一種「惡意方案」,其中「知道雜湊函數的演算法」本身就是一個後門! 只要有人知道 SHA-2 的算法,他就可以破解這個方案。
在隨機預言機模型下,由於沒有人「知道」雜湊函數的算法,這個後門不會被觸發,因此方案是安全的;但在現實世界中,任何人都能查到 SHA-2 的算法,所以這個方案就會被攻破。
這些研究結果,介於「驚為天人」和「廢話!」之間。驚人之處在於:這些方案無論如何實例化雜湊函數,最終都會崩潰! 這表明隨機預言機模型本身可能就是一個陷阱! 但這種反例的存在也很愚蠢,因為,拜託……這不是廢話嗎!?事實上,我們真正揭示的只是:我們的人工模型本來就是人工構造的。如果你設計的方案在攻擊者知道雜湊函數的算法時就會崩潰,那麼,它當然會被攻破啊! 這根本不需要什麼天才才能看出來,這種設計方式肯定是行不通的。
儘管如此,理論學者們還是開心地繞場慶祝了一圈,然後轉向破壞其他人的樂趣。而工程師們則等到這群理論學者失去興趣後,翻了個白眼,然後說:「我們就同意別部署這種明顯愚蠢的方案吧。」接著,他們又繼續開發那些 僅在隨機預言機模型下可證安全 的方案——而這種情況,已經持續了大約 28 年。
但理論學者並沒有完全錯,對吧?
這是一個價值 100 億美元的問題。
如前所述,許多「反例方案」都是刻意構造的,目的是為了證明隨機預言機模型的危險性。但這些方案的設計都過於荒謬,以至於沒有人真的會在實際系統中部署它們。如果你的簽名方案裡有 40 行代碼,基本上在大聲喊著「注意:如果你知道 SHA-2 的算法,就能解鎖這個後門!」,那麼最好的解決方案不是去討論這段代碼是否「合理」,而是直接刪掉它,然後格式化你的硬碟三次,最後再拿去燒掉。對於工程師來說,這些刻意構造的反例並不構成真正的威脅。
但風險依然存在。
隨著密碼學方案變得越來越複雜和強大,這種風險正在擴大。早在 5 年前,我在另一篇部落格文章中就已經提出了這個警告,現在看來,它依然適用:
https://blog.cryptographyengineering.com/2020/01/05/what-is-the-random-oracle-model-and-why-should-you-care-part-5/
「這類惡意方案意外出現在現實世界中的機率雖然很低,但隨著密碼學協議變得越來越複雜,這種可能性將會上升。例如,Google 已經開始部署多方安全計算(MPC),而其他人則開始推出零知識證明(ZK)協議,這些協議甚至可以以密碼學的方式運行任意程式碼或證明程式碼執行的正確性。我們無法完全排除 CGH 和 MRH 類型的反例在這些複雜場景中發生的可能性——只要開發者稍有不慎,它們可能真的會出現。」
讓我們來深入探討這個問題。
近年來,密碼學領域出現了一類新的技術:簡潔「零知識證明(ZK)」和「可驗證計算(verifiable computation)」。這些技術允許不可信方提供一個證明,證明他們確實執行了一段特定的程式碼,而且結果是正確的,而不需要透露具體的計算過程。簡單來說,這些系統允許「證明者」(Prover) 向「驗證者」(Verifier) 證明以下事實:(1) 我知道一個 [公開已知] 的程式的輸入,使得 (2) 當該程式在此輸入上運行時,會輸出 「True」。
這些系統的一個精妙之處在於,當程式執行完畢後,我能夠撰寫一份簡短(即「簡潔」)的證明,以證明兩個事實均為正確。更妙的是,我可以將這份短證明(有時稱為「論證」)交予世界上任何人。他們只需運行一個驗證演算法來檢查該證明是否有效;若驗證結果吻合,就無需重新執行原始計算。關鍵在於,即使在非常複雜的程式執行情況下,驗證證明所需的時間通常遠少於重新檢查程式執行所需的時間。由此產生的系統被稱為知識論證,並以各種炫酷的縮寫聞名:SNARGs、SNARKs、STARKs,甚至有時也稱作IVC。(以太坊圈子有時將這些統稱為「ZK」,但出於歷史原因,我們在此不再探究。)
這項技術已被證明是密碼世界一個令人振奮且必要的解決方案,因為該領域正面臨著一個真正的難題。具體來說:大家都注意到區塊鏈非常緩慢。這些系統需要數以千計的不同電腦來驗證(即檢查每筆金融交易的有效性),從而對交易吞吐量產生了極大的限制。
“簡潔”證明系統正好為這一難題提供了完美的解決方案。
與其將數以百萬計的個別交易提交至一個龐大且緩慢的區塊鏈中,不如將區塊鏈拆分開來。稱為「rollups」的獨立伺服器能夠分別驗證大量交易的批次。它們各自可利用簡潔證明系統來證明,自己正確地執行了交易驗證程式,處理了所有這些交易。基層區塊鏈不再需要審查每一筆交易;只需驗證由rollup伺服器產生的短證明,就能(神奇地!)確保所有交易皆已獲得驗證,而基層區塊鏈的工作量卻大幅減少。理論上,這使得區塊鏈的吞吐量能夠獲得巨大提升,同時基本不犧牲安全性。
更酷的是,在某些情況下,這些證明系統甚至可以遞歸地應用。這歸功於一個巧妙的特性:畢竟,驗證證明的演算法本身也只是一個電腦程式。因此,我可以將該程式作用於其他證明作為輸入——接著利用證明系統來證明我正確地執行了該程式。
https://medium.com/@denniswon/unlocking-the-power-of-recursive-zk-snarks-applications-and-implementations-83666a22b54a
舉一個更具體的應用例子:
試想有 1,000 台不同的伺服器,各自運行一個程式來驗證一批 1,000 筆獨立的交易。每台伺服器均生成一份簡潔證明,以證明其程式執行正確(亦即,其交易批次無誤)。 接著,一台不同的伺服器可以接收這 1,000 份不同的證明,並運行一個驗證程式,逐一檢查這 1,000 份證明的正確性,最終輸出一份證明,證明它正確地執行了該程式。 最終結果是一份「短小」的證明,證明全部 1,000,000 筆交易皆正確!
我甚至畫了一張不算太精妙的圖,試圖說明其運作方式:
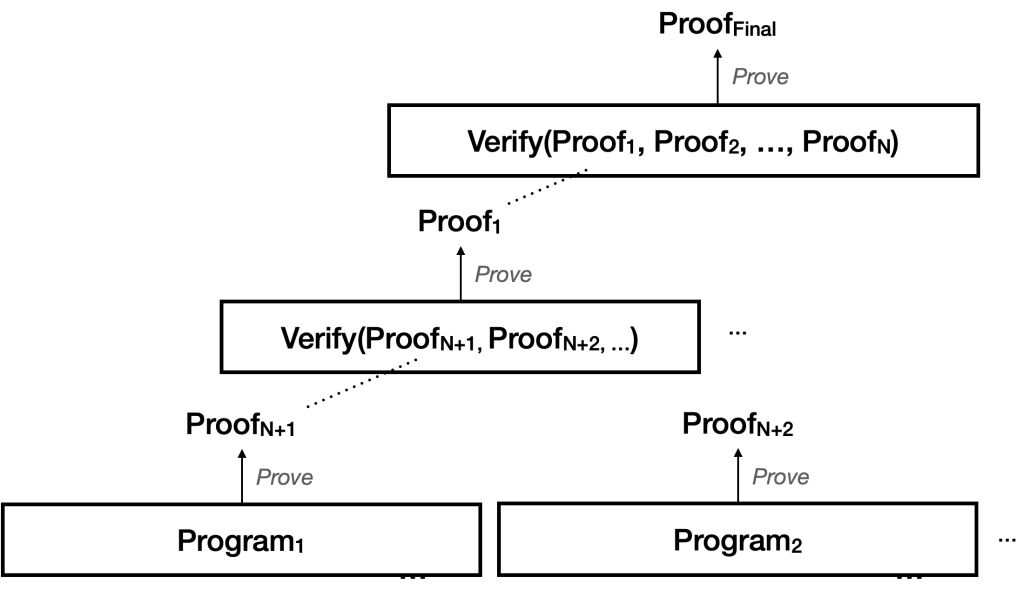
以上是一個遞歸證明使用的例子。在最底層,我們有一些實際程式,每個程式都擁有獨立的證明。接著在上一層,有一個程式專門用來驗證底層的那些證明。而在頂層,又有另一個程式負責驗證第二層所產生的多個證明!(許多程式未予展示。)
這種遞歸技術確實非常實用,我保證它在後續將會發揮重要作用。
那又怎樣?
你可能會問:這跟隨機預言機的反例有什麼關係?
由於這些證明系統現在已經強大到可以運行任意程式(通常是以算術電路或布爾電路的形式),因此存在一種可能性,讓狡猾的反例性「後門」被偷偷嵌入到我們所驗證的程式中。這意味著,即便實際的證明方案在程式碼中沒有明顯的後門,被驗證的程式仍可能執行一些詭異的操作,從而破壞整個系統的安全性。我們的實務工作者朋友們將無法再運用他們(極為合理的)「不要部署明顯有疑慮的程式碼」這一經驗法則,因為儘管他們的實現程式可能不會做出愚蠢的事情,但某些用戶卻可能嘗試將其與一個惡意程式一同運行。
(一個很好的類比是:想像你的任天堂系統本身沒有內建漏洞,但任何特定的遊戲可能會偷偷夾帶一段惡意程式碼,足以摧毀整個系統。)
https://gbatemp.net/threads/is-zelda-oot-3d-the-only-exploit-for-gateway-3ds.385134/
中場哲思
事情已經進展得相當迅速,而且未來還有更多內容等待揭曉。
為了讓各位稍作喘息,我們暫停一下,聊聊哲學、形而上學(或者說是元密碼學?),或者僅僅探討一下人生的意義。更具體地說,這個時候我們需要停下來,問一個非常合理的問題:這個威脅模型究竟有多重要?而這個威脅模型到底是什麼?
請允許我解釋一下。試想,我們擁有一個基本上沒有後門的證明系統。這個系統可能有也可能沒有可證明安全性,但就其本身而言,即使你使用像 SHA-3 這樣的具體雜湊函數來實現它,證明系統本身也不含有任何明顯的後門,不會因此而出現故障。
現在,再想像有人寫了一個名為 Verify_Ethereum_Transactions_EVIL.py 的程式,我們打算用我們的證明系統來執行並驗證它。從這個名字來看,我們可以推測這個程式是由一個可疑的工程師開發,其惡意地決定在程式碼中加入一個「後門」!這個程式不僅僅是按照預期來驗證以太坊交易,而是做了一些更惡劣的事情:
「給定一些輸入,如果該輸入包含 1,000 筆有效的 Ethereum 交易則輸出 True…
或
如果輸入(或程式碼本身)包含了證明系統所使用的雜湊函數的描述,也輸出 True。」
這對你的密碼貨幣網路來說將是極其糟糕的情況!任何聰明的用戶都可以提交無效的以太坊交易給這個程式驗證,而它卻會愉快地回傳 “True”。如果某個密碼貨幣網路因此信任這個證明(認為「這些交易確實有效」),那麼你就可能利用這個漏洞竊取大量資金。
但我要說得很清楚:在你的密碼貨幣網路中部署這樣的程式本身就是極其愚蠢的行為。
證明系統的核心目的在於證明你已經成功執行了一個程式,包括其中所包含的任何邏輯。如果這些程式中內含明顯的後門,那麼證明你執行了這些程式也意味著你可能已經觸發了其中的後門。如果撰寫你關鍵軟體的人懷有惡意,或是你沒有仔細審查他們的程式碼,最終你只會追悔莫及。而且,增加後門的方式有很多很多!(僅舉一例,過去曾有一個名為 “Underhanded C Contest” 的比賽,人們在比賽中競相撰寫充滿難以檢測的惡意程式碼的 C 程式,結果確實令人印象深刻!)
https://www.underhanded-c.org/
因此,有必要問問自己,這樣的情形是否真有那麼令人驚訝。過去我們知道:(1) 如果你的愚蠢密碼學方案中包含一些奇怪的程式碼,致使其對「任何懂得如何計算 SHA-2 的人」都變得不安全;那麼 (2) 在現實世界中它確實是不安全的,因為任何傻瓜都可以下載 SHA-2 的程式碼;而 (3) 你絕不應該部署那些含有明顯後門的方案。
有了這樣的背景,讓我們來談談可能會發生哪些糟糕的情況。這些情況可以分為「最佳情形」、「次差情形」以及「天啊,糟透了」這三種。
在最佳情形下,此類攻擊可能只是將那令人害怕的後門程式碼從密碼證明系統中移出,轉而進入那些可以餵給證明系統的模組化「應用程式」。你仍然需要確保方案的實現中沒有愚蠢的後門——例如某段特殊程式碼,一旦識破 SHA-2 的程式碼就會讓一切崩潰。但如今你也必須確保每個你用這個系統執行的程式都不含有類似的後門。明確地說:反正你本來就得對你的程式碼進行後門審查!
公平地說,這些密碼後門的本質可能比一般的軟體後門更為微妙。我的意思是,一般的軟體審查者可能無法察覺,而只有經驗豐富的密碼學家才會發現某些可疑之處。但即便這個漏洞難以識別,它仍然是一個漏洞——存在於某一段特定程式碼中——而且最關鍵的是,只有在你部署它時,才會影響到你自己的應用程式。
當然,還存在更糟的可能性。
在次差情形下,也許這個漏洞可以以某種巧妙且極為微妙的方式內建於應用程式碼中,使得程式碼審查者即便知道該如何尋找也無法輕易發現——也許它甚至能夠被密碼學地混淆,令任何程式碼審查都無法察覺!遞迴證明系統在這方面尤其令人擔憂,因為這個「漏洞」可能存在於遞迴證明樹的多個層次中,而你可能無法取得所有低層程式碼的檢視權限。(例如,我們可以想像,一個遞迴驗證程式可能僅僅接收一個程式的雜湊值(或承諾)。接著,一個證明者可以簡單地聲明:「好吧,我知道有一個真實的程式,其雜湊值符合這個承諾,而且我也知道一個能使該程式滿足條件的輸入。」這意味著,技術上來說,每個審核者無法獲得程式本身,而只能取得程式的雜湊值。我在這裡採用了許多概略性的描述,但這一切都是可能的。)或許我們需要審查的「惡意程式行為」的集合已經大到無法用簡單的經驗法則來捕捉那些不良程式碼!
這實在令人感到恐怖。但這當然還不是最糟的情形。
而最差(「糟糕透了!」)的情形是:在遞迴證明中,還有一個更可怕的理論性可能性。請記住,一個單一的頂層遞迴證明可以遞迴地驗證數以千計的不同程式。這些程式中,許多很可能是由謹慎且誠實的開發者所撰寫,而另一些則可能是詐騙者所寫。顯然,如果詐騙者的程式中存在漏洞(或缺陷),我們理應預期這些漏洞會使得詐騙者自己的程式在它們應達成的目標上變得不安全。到目前為止,這一切都不足為奇。但理想情況下,我們應該希望詐騙者程式中的任何後門都僅局限於詐騙者自己的程式之中。它們不應該「跨越程式邊界」,從而破壞遞迴證明堆疊中其他誠實、良好編寫程式的安全性。
現在,試想一種情況:這種隔離機制並不存在。也就是說,樹中任何一個「程式」中的一個巧妙漏洞,都可能以某種方式使整個證明樹中任何其他程式(證明) 都變得不安全。這就像是將一個惡意程式植入 Linux 系統,然後利用它來攻擊 Linux 內核,進而破壞系統上任何應用程式的安全性。也許這聽起來不太可能?對我來說,這實在是異想天開,但再說一次,我們此刻正處於一個充滿奇想的世界。誰知道未來會有什麼可能性呢!
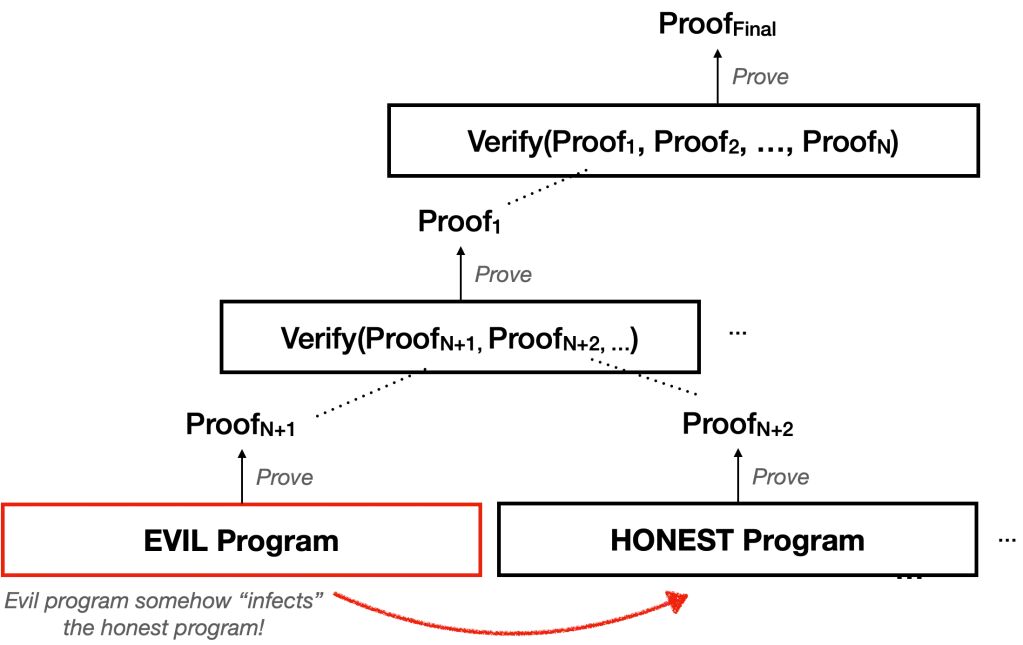
這是最糟糕的情形。我不認為這種狀況會發生,但……誰知道呢?
這正是當我們脫離可證明安全的範疇後,可能出現的可怕現象。若缺乏我們可以依賴的基本安全保證,可能面臨的攻擊種類雖然有限,但也可能是根本無限的!