
击败随机性以创造理想编码
原文:https://www.quantamagazine.org/researchers-defeat-randomness-to-create-ideal-code-20211124/
翻译:Kurt Pan
通过精心构造多维且具有强连通性的图,一组研究人员终于创造了一个期待已久的局部可检验码,该编码可以立即暴露其是否已被损坏。
假如你正在尝试传输一条消息:你会将每个字符转换为比特串,再将每个比特转换为一个信号,然后通过铜导线、光纤或空气将信号发送出去。即使你尽可能地小心,对方接收到的东西也可能与你一开始想发送的不同。噪声可永远不会停止破坏。
1940 年代,计算机科学家首先遇到了不可避免的噪声问题。五十年后,他们想出了一个优雅的方法来回避它:是否可以对一条消息进行编码,以使得在接收者阅读之前就可以明显地看出是否已经出现乱码?一本书不能通过封面来评判,但这条信息可以。
他们将这个性质称为局部可检验性(local testability),因为这样的消息通过仅仅在几个点进行超快速的检验,就可以确定其正确性。在接下来的 30 年里,研究人员在创建这样的检验方法方面取得了一些实质性的进展,但其努力依然不够,许多人认为局部可检验性永远不会以其理想形式实现。
在11 月 8 日发布的预印本[1]中,魏茨曼科学研究所的计算机科学家 Irit Dinur和耶路撒冷希伯来大学的四位数学家Shai Evra、Ron Livne、Alex Lubotzky和Shahar Mozes发现了它。

“这是我所知道的数学或计算机科学中最非凡的事件之一,”华威大学的Tom Gur说,“这是整个领域的圣杯。”
他们的新技术将消息转换为“超级金丝雀”,这种对象比已知的任何其他消息都更能证明其自身的健康状况。隐藏在其上层结构任何地方的重要出错都可以通过在几个点进行的简单检验而变得明显起来。
“这似乎是不可能做到的事,”哈佛大学的 Madhu Sudan说, “但这个结果突然说事实上你可以做到。”
大多数先前的数据编码方法都依赖于某种形式的随机性。但对于局部可检验性,随机性无济于事。取而代之的是,研究人员必须设计出一种对数学来说全新的高度非随机的图结构,并以此为基础建立新方法。这既是由于理论上的好奇,也是使信息尽可能具有韧性的努力在实践上的进展。
1编码入门
噪声在通信中无处不在。为了系统地分析它,研究人员首先将信息表示为比特序列,即0/1串 。然后我们就可以将噪声视为会导致某些比特翻转的随机影响。
有许多方法可以处理噪声。考虑一条像 01 这样短而简单的消息。通过重复它的每一比特三次来修改它,得到 000111。即使被噪声破坏了比如说第二和第六位,将消息改变为 010110 , 接收者仍然可以通过两次计多数来纠正错误(一次为 0,一次为 1)。
这种修改消息的方法称为编码。在这种情况下,由于该编码还带有修复错误的方法,因此称为纠错码。编码就像字典,每个字典都定义了一组特定的码字,例如 000111。
一个运行良好的编码必须具有多个性质。首先,其包含的码字不应太相似:如果一个编码包含码字 0000 和 0001,则只需要一个比特翻转的噪声就可以混淆这两个码字。其次,码字不宜过长。重复比特可能会使消息更可靠,但也会使发送时间更长。
这两个性质称为码距和码率。一个好的编码应该具有较大的码距(在不同的码字之间)和较高的(传输真实信息的)码率。但是怎么能同时获得这两个性质呢?1948 年,克劳德·香农 (Claude Shannon) 表明,任何随机选择码字的编码都会在这两种特性之间得到近乎最优的权衡。然而,完全随机选择码字会导致非常难于查找的不可预测字典。换句话说,香农证明了好编码是存在的,但他给出的制作它们的方法并不奏效。
“这是一个存在性的结果,”哥伦比亚大学的 Henry Yuen 说。
在接下来的 40 年里,计算机科学家致力于找出接近随机理想情况的比特非随机排列方法。到 1980 年代后期,他们的编码已被用于从 CD 到卫星传输的所有领域。
1990 年,研究人员提出了局部可检验性的概念。这是一个不同的性质,如果你随机选择一个编码,正如香农所建议的那样,那么它不可能是局部可检验编码。这些编码是随机编码宇宙中的白化蝴蝶——非常美丽,如果它们存在的话。
“实际上即使要证明它们的存在性也需要更多的努力,”Yuen说。“更不用说提出一个显式实例了。”
2图即编码
要理解为什么可检测性难以获得,我们需要将消息不仅仅看作比特串,而要看作一个图:由边(线)连接的顶点(点)的集合。自从在香农的结果两年后理查德·汉明 (Richard Hamming) 创建了第一个巧妙的编码以来,这种等价性一直是理解编码的核心。(在R. Michael Tanner 1981年的一篇论文[2]之后,图观点变得特别具有影响力。)
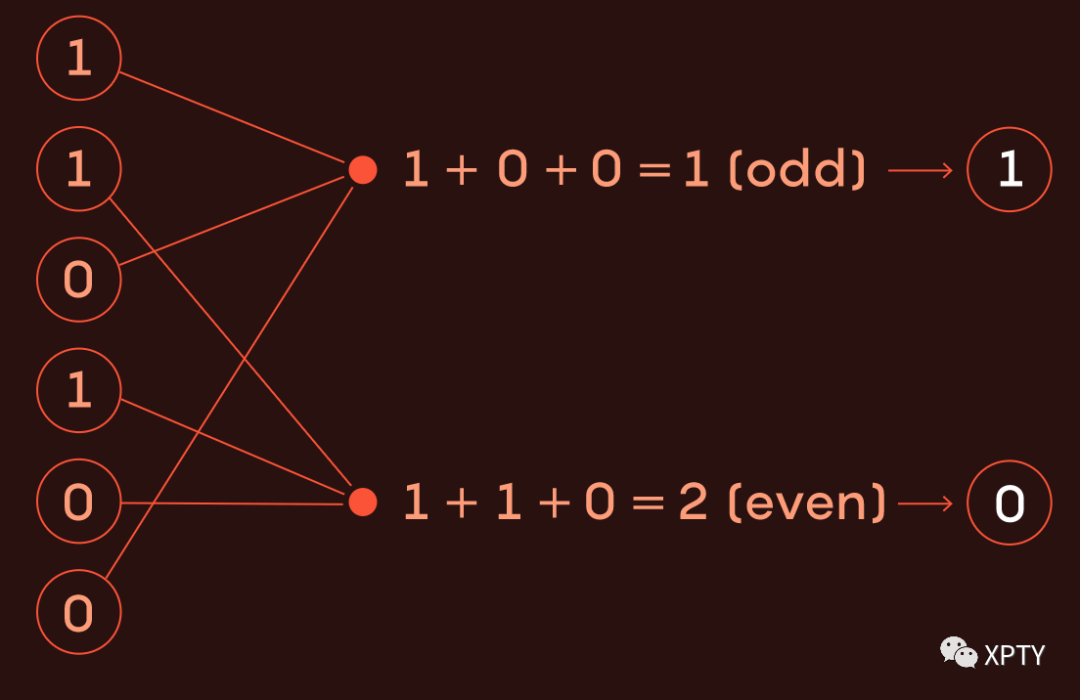
汉明的工作为 1980 年代无处不在的纠错码奠定了基础。他提出了一条规则,即每条消息都应该匹配一组“收据”,这些收据记录了相应比特的“账目”。更具体地说,每条收据都是从消息中精心选择的比特子集的求和。当这个求和值为偶数时,收据被标记为 0,当它有奇数值时,收据被标记为 1。每条收据由一个比特表示,换句话说,研究人员称之为奇偶校验或奇偶校验位.
汉明指定了将收据附加到消息的过程。然后,收件人可以通过尝试复现收据、自己计算求和来检测错误。这些汉明码工作得非常好,它们是将编码视为图以及将图视为编码的起点。
“对我们来说,考虑图和考虑编码是一回事,”德克萨斯大学奥斯汀分校的 Dana Moshkovitz 说。
要从编码得到图,要从一个码字开始。对于每一比特信息,绘制一个顶点(或节点),称为数字节点。然后为每个奇偶校验位绘制一个节点,这些被称为奇偶校验节点。最后,绘制从每个奇偶校验节点到应该相加形成其奇偶校验值的数字节点的线。于是由编码创建了一个图。
将编码和图视为等价已成为设计编码艺术中不可或缺的一部分。1996 年,Michael Sipser 和 Daniel Spielman 使用该方法从一种称为扩展图的图中创造了一个突破性的编码。他们的编码仍然无法提供局部可检测性,但它在其他方面被证明是最优的,并最终成为新结果的基础。


3扩大可能性
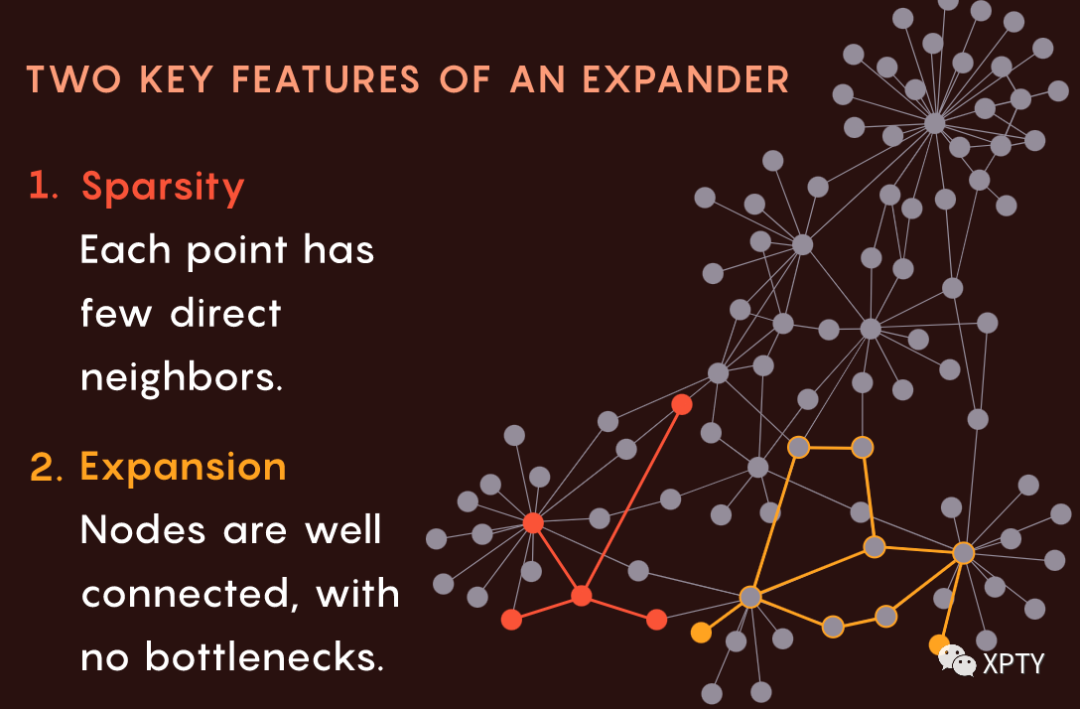
扩展图特殊在于两个看似矛盾的性质。首先,它们是稀疏的:每个节点都连接到相对较少的其他节点。其次,它们具有扩展性(也是扩展图名字的由来),意思是没有任何节点集合可以成为很少有边通过的瓶颈。换句话说,尽管连接是稀疏的,每个节点都与其他节点连接良好。
“为什么会有这种东西存在?” Evra说。“如果很稀疏,那么就没有那么紧密的连接,这样想并不牵强。”
但是扩展图实际上非常容易创建。如果以随机方式构建图,即在节点之间随机选择连接,则不可避免地会产生扩展图。它们就像是纯粹的、未经提炼的随机性的来源,使它们成为香农指出的良好编码的天然构造模块。
Sipser 和 Spielman 研究了如何将扩展图转换为编码。他们提出的码字是由许多由汉明码产生的更短的字构成的,他们称之为小码。他们的码字的比特被表示为扩展图的边,小码的所有收据都在每个节点上表示。
实际上,Sipser 和 Spielman 表明,如果你在每个具有良好性质的节点上定义小码,那么由于图连接良好,这些性质会传播到全局编码。这种传播为他们提供了一种创建良好编码的方法。
“扩张,扩张,再扩张,” Evra说,“这就是成功的秘诀。”
然而,局部可检验性是不可能的。假设你有一个来自扩展图编码的有效编码字,并且从一个节点中删除了一个收据(奇偶校验位)。这将构成一个新编码,因为他们需要满足的收据会少一个,它将比第一个编码具有更多的有效码字。对于使用原始编码的人来说,这些新码字将满足大多数节点的收据(除了收据被删除的节点)。然而,由于两个编码的码距很大,看起来正确的新码字与原始码字集合相距甚远。局部可检验性与扩展图编码完全不兼容。
为了获得可检测性,研究人员必须弄清楚如何对抗以前非常有用的随机性。最后,研究人员到达了随机性无法达到的地方:进入更高维度。
4随机性的反面
他们能否做到这一点并不总是清晰的。到 2007 年实现了局部可检测性,但却是以其他参数为代价,例如码率和码距。特别地,这些参数会随着码字变大而退化。在一个不断寻求发送和存储更大信息的世界中,这些退化是一个主要缺陷。(尽管在实践中,即使是已有的局部可检测码也已经比大多数工程师需要使用的更强大了。)
可以找到具有最佳码率、码距和局部可检测性(且三者即使在消息渐进增长时都保持不变)的编码的假设被称为**猜想**。先前的结果使一些研究人员认为解决方案必然会出现。但进展却开始放缓,并有其他结果表明这一猜想可能是错误的。
“社区中的许多人认为这只是一个好到不可能成真的梦想。”Gur 说, “情况看起来很严峻。”
但在 2017 年,出现了新的想法来源。Dinur 和 Lubotzky 在参加以色列高等研究院为期一年的研究项目时开始合作。他们开始相信,数学家Howard Garland 1973 年的结果可能正是计算机科学家所寻求的。普通扩展图本质是一维结构,每条边仅在一个方向上延伸,而 Garland 创造了一个数学对象,可以将其解释为跨越更高维度的扩展图,比如说将图的边重新定义为正方形或立方体。
Garland 的高维扩展图看起来具有非常适合局部可检测性的特性。它们必须从头开始精心构建,使它们成为随机性的自然对立面。它们的节点相互关联,以至于它们的局部特征与从全局看它们几乎没有区别。
“对我来说,高维扩展图是一个奇迹,”Gur 说。“你对该对象的一个部分进行微小的调整,一切都会随之改变。”
Lubotzky 和 Dinur 开始尝试根据 Garland 的工作构造一个可能解决猜想的编码。Evra、Livne 和 Mozes 很快加入了团队,他们每个人都是高维扩展图不同方面的专家。
很快他们就在研讨会和演讲中展示了他们的工作,但并不是每个人都被说服高维扩展图的理论会为前进铺平道路,毕竟要完全理解它需要爬上陡峭的学习曲线。
“当时它看起来像是太空时代的技术,是计算机科学中从未见过的复杂而奇特的数学工具。” Gur 说:“似乎是有点矫枉过正的技术。”
2020 年,研究人员陷入困境,直到他们意识到其实可以不依赖最复杂的新工具,只需要他们从高维扩展图中获得的灵感就足够了。
5传播错误
在他们的新工作中,作者想出了如何组装扩展图来构造一个新图,从而获得最佳形式的局部可检验码。他们称他们的图为左右Cayley复合体( left-right Cayley complex)。
正如 Garland 的工作,他们图的构造模块不再是一维的边,而是二维的正方形。码字中的每个信息比特都分配给一个正方形,奇偶校验位(收据)分配给边和角(它们是节点)。因此,每个节点定义了可以连接到它的比特(或正方形)的值。
要了解他们的图是什么样子,想象一下从内部观察它,站在一条边上。他们构建该图使得每条边都附属有固定数量的正方形。因此从你的有利位置看,你会感觉好像是从一个小册子的书脊向外看。但是,从小册子页面的其他三个侧面,你会看到新小册子的书脊也从它们分出。小册子会从每个边分叉直到无穷。
“可视化是不可能的。这就是重点,”Lubotzky说。“这就是为什么它如此复杂。”

至关重要的是,这个复杂的图依然具有扩展图的属性,例如稀疏性和连通性,但同时具有更丰富的局部结构。例如,一个坐在高维扩展图的一个顶点的观察者可以使用这种结构直接推断整个图是强连接的。
“随机性的反面是什么?是结构。”Evra说。“局部可检测性的关键是结构。”
要看到这个图如何生成局部可检测码,考虑在扩展图编码中,如果某个比特(即边)出错,则只能通过检查其紧邻节点的收据来检测该错误。但是在左右Cayley复合体中,如果一个比特(一个正方形)有错误,则可以从多个不同的节点看到该错误,包括一些甚至没有通过边相互连接的节点。
通过这种方式,在一个节点上的检测可以揭示来自远处节点的错误信息。通过使用更高的维度,图最终以超出我们通常认为的连接的方式连接。
除了可检测性之外,新编码还保持了码率、码距和其他所需性质(即使码字渐进增长),证明了猜想是正确的。它建立了纠错码的最新技术,也标志着将高维扩展图的数学应用于编码的第一个实质性回报。
“这是看待这些对象的全新方式,”Dinur 说。
实际和理论应用应该很快就会出现。不同形式的局部可检测码现在正在去中心化金融中使用,一个最优版本将允许更好的去中心化工具出现。此外,计算机科学中有完全不同的理论构造,称为概率可检验证明PCP,它们与局部可检测码有一定的相似性。现在我们已经找到了后者的最优形式,前者的破纪录版本似乎很可能会出现。
新编码标志着一个概念上的里程碑,这是迄今为止超越由随机性设置的编码界限的最大一步。剩下的唯一问题是,信息铸造的良好程度是否存在真正的限制。
参考资料
预印本: https://arxiv.org/abs/2111.04808
[2]1981年的一篇论文: https://ieeexplore.ieee.org/abstract/document/1056404