
【全同态加密】Phantom: RISC-V FHE VM
❝原文:https://phantom.zone/posts/phantom-release1
作者:Janmajaya Mall,Jean-Philippe Bossuat
译者:Kurt Pan
今年早些时候,我们发布了 Phantom 的原型,即 RISC-V FHE VM。今天,我们很高兴发布 Phantom 的首个端到端实现。
https://phantom.zone/posts/phantom-fhe-vm https://github.com/phantomzone-org/phantom
简言之,Phantom 是一个使用 FHE 电路实现 RV32I ISA 的 RISC-V FHE VM。因此,Phantom 可以在任意输入上执行任意 RISC-V 二进制文件,其中输入和 RISC-V 二进制文件都是加密的。这意味着,程序的执行者(即服务器)无法从执行轨迹中获知关于程序或输入的任何信息。
由于 Phantom 是一个 VM,它不受电路模型限制的约束,因此可以具有:
依赖输入的执行 任意运行时 无嵌套分支导致的指数级成本
Phantom 最重要的特性或许在于它能够很好地融入 Rust → RISC-V 编译流水线:开发者可以用 Rust 编写程序,无需担心如何将其适配到 FHE。
入门指南
要开始使用 Phantom,请查看 README。特别是,可参考 template 示例或更复杂的 OTC 示例。
https://github.com/phantomzone-org/phantom?tab=readme-ov-file#how-to-use-phantom https://github.com/phantomzone-org/phantom/tree/main/compiler-tests/template https://github.com/phantomzone-org/phantom/tree/main/compiler-tests/otc
性能
对于约 1KB 的加密程序和约 4KB 的加密内存,在 32 核上平均每个周期大约需要 655ms(在 AWS r6i.metal 实例上进行基准测试)。该实现高度可并行化,我们预期性能会随着核心数量的增加而提升。瓶颈和改进空间技术细节请查看下文。
Phantom - 技术入门
本文是对 Phantom 作为 RISC-V FHE-VM 的技术深入探讨。
所有活动组件
下图是 Phantom 流水线的高级示意图:
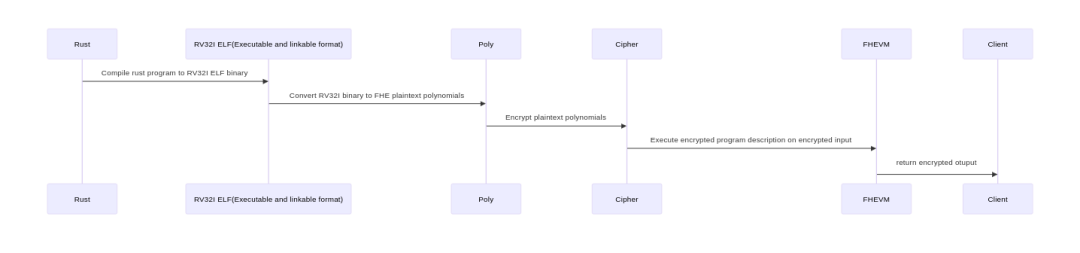
Rust -> RV32I ELF(可执行和可链接格式):Rust 程序被编译成 RV32I ELF 二进制文件。 RV32I ELF(可执行和可链接格式) -> Poly:RV32I 二进制文件被转换为与同态加密方案的多项式代数兼容的表示形式。此步骤解析指令、解码它们,并将它们重新编码为 的元素。 Poly -> Cipher:RV32I 二进制文件的多项式表示被加密。 Cipher -> FHEVM:RISC-V 二进制文件的加密多项式表示被同态解释执行固定数量的周期。 FHEVM -> Client:客户端获取包含程序执行输出的加密带。
步骤 1 由 Rust 编译器开箱即用地提供。步骤 2 只是解析 ELF 文件、解码指令,并将指令编码为 FHE 明文多项式。步骤 3 是简单的加密,步骤 5 是平凡的——将输出密文发送回客户端。
因此,本文档的其余部分将重点关注 FHEVM 的实际构造。
RISC-V VM 入门
虚拟机由 4 个主要构建块组成:ROM、RAM、Registers 和 PC(程序计数器)。
ROM 是只读存储器,存储程序的指令。RAM 是读/写长期存储,是程序的内存。Registers 充当临时的短期内存,以避免频繁的 RAM 访问[^1]。PC 跟踪下一条指令的地址。
在每个周期,由 PC 寻址的指令从 ROM 中读取并解码。然后执行该指令。指令的执行要么更新 RAM、PC,要么更新 Registers[^2]。
我们可以根据指令更新三者(RAM、PC、Registers)中的哪一个来对指令进行分类。
Arithmetic 指令使用 registers 作为输入/输出目标执行算术运算。 Load 指令从 RAM 加载一个值到 register。 Store 指令将一个值从 register 保存到 RAM。
Arithmetic、load 和 store 指令都有将 PC 增加 4 的副作用。
Branching 类型指令有条件地将 PC 设置为非平凡值,否则将其增加 4(与 arithmetic、load 和 store 指令相同)。
除了经典的 fetch-decode-execute 流水线外,还有一些 RISC-V 特定的细节:
有 32 个 registers [x0,...,x31],每个 32 位大小。register x0始终为 0,所有对x0的写入都被忽略。指令为 32 位大小,在 ROM 中按字对齐存储。 RAM(即内存)按字节寻址。
总结一下,一个周期:
从 ROM 获取由 PC 寻址的指令: instruction ← ROM[pc]。解码指令以提取 opcode:操作类型,rd:返回 register,rs1:输入 register 1,rs2:输入 register 2,imm:立即数,硬编码在指令中的常量。执行指令,可以是 Arithmetic: x[rd] ← op(x[rs1], x[rs2], imm, pc)且pc ← pc + 4。Load: x[rd] ← RAM[x[rs1]+imm]且pc ← pc + 4。Store: RAM[x[rs1]+imm] ← x[rs2]且pc ← pc + 4。Branching:如果 condition,pc ← pc + imm,否则pc ← pc + 4。回到 1。
简单周期执行示例
这里有一个小程序来说明 fetch-decode-execute 语义。它将 x1 加到 x2 直到 x2 大于 x3,然后将其存储到 RAM:
0x0000: 0x00208133
0x0004: 0xfe316ce3
0x0008: 0x00202023
周期 1: Fetch pc = 0x0000处的指令:0x00208133。Decode: 0x00208133=0000000 00010 00001 000 00010 0110011。我们有op = 000 | 0110011即ADD,其中rs1=0b00001,rs2=0b00010且rd=0b00010。Execute:执行 add(x1, x2) -> x2并设置(pc = 0x0004) ← (pc = 0x0000) + 4。周期 2: Fetch pc = 0x0004处的指令:0xfe30eee3。Decode: 0xfe316ce3=1111111 00011 00010 110 11001 1100011。我们有op = 110 | 1100011,即BLTU(无符号比较),其中rs1 = 0b00010,rs2=0b00011且imm=sext(0b111111111100) = -4。Execute:如果 x2 < x3则设置(pc = 0x0000) ← (pc = 0x0004) - 4,否则增加(pc = 0x0008) ← (pc = 0x0004) + 4。
周期执行将在 pc = 0x0000 和 pc = 0x0004 之间来回切换,直到 x2 >= x3。一旦 x2 >= x3,pc 就增加默认值(4),将其设置为 pc = 0x0008。
周期 n Fetch pc = 0x0008处的指令:0x00202023。Decode 0x00202023 = 0000000 00010 00000 010 00000 0100011,从op = 010 | 0100011可知它是SW(store word),其中rs2=0b00010,rs1=0b00000且imm=0b000000000000。Execute:将 x2存储到 RAM 的地址(x0=0) + (imm=0) = 0并设置(pc = 0x000c) ← (pc = 0x0008) + 4。
基于 GLWE 的 FHE 的一些概念
在其核心,同态加密(HE)允许对加密数据进行计算:给定编码明文的密文,可以应用某些代数运算(如加法、乘法)来获得解密为原始明文上这些运算结果的密文。
在基于 GLWE 的 FHE 方案中,加密将明文编码为环上的多项式(或 torus 向量),并支持加法、乘法运算和 automorphisms。
我们在 Torus (所有实多项式的集合)上工作。算术运算在系数上模 执行,在多项式级别模 执行。
我们记 ,并偶尔引用 (整数多项式的集合)。
明文代数
明文代数遵循 的算术。也就是说,我们可以将消息相加,将它们乘以整数多项式( 的),这包括整数常量和单项式 。我们还可以应用 automorphisms:映射 ,其作用相当于置换系数(最多带有符号变化)。
GLWE Ciphertext
rank 为 的 GLWE ciphertext 是一个元组 ,其中 ,这里 , 是具有小方差的误差多项式, 且 。
解密执行为 。只要 足够小, 就可以被恢复。
容易看出,这种加密对于密钥的任何线性函数(加法、乘以常数等)都是线性同态的。
GGLWE Ciphertext
GGLWE ciphertext 是加密 的 GLWE 的元组,其中 且 是分解基。更具体地:
这种类型的 ciphertext 支持以下运算:
GGSW 密文
GGSW 密文是加密 的 GGLWE 的元组,其中 。更具体地:
External Product
GGSW ciphertext 格式支持一种称为 external product 的同态运算:
我们将看到 external product 是一个关键运算,它是 Phantom 中使用的许多更高级同态运算的核心。
Phantom 的 FHE 构建块
Phantom 的高级概述
在深入 Phantom 的各个组件和技术细节之前,我们将对其核心组件进行高级概述。
VM 由四个主要组件组成:
程序计数器,指向要执行的指令:PC,一个加密的 u32。指令,存储在只读加密内存中:ROM,一个 32 x ⌈#instructions / N⌉ 的 GLWE 矩阵。 Registers,用作短期加密存储:REGISTERS,一个 32 x ⌈32 / N⌉ 的 GLWE 矩阵。 可写内存,用作长期加密存储:RAM,一个 32 x ⌈ram_size / N⌉ 的 GLWE 矩阵。
ROM、REGISTERS 和 RAM 都可以使用相同的 API 访问:
在某个加密地址读取加密值。 在某个加密地址写入加密值。
此外,在每个周期,VM 将更新以下之一:
以非平凡方式更新程序计数器(而不是将其增加 4)。 通过存储从 REGISTERS 读取的值到某个地址来更新 RAM。 通过写入从 RAM 读取的值或写入算术运算的结果来更新 REGISTERS。
加密内存
ROM、RAM 和 REGISTER 的内存结构为 32 x #u32 矩阵:
┌─────────────┬─────────────┬─────────────┬─────┐
│ u32_{0,0} │ u32_{0,1} │ u32_{0,2} │ ... │
│ u32_{1,0} │ u32_{1,1} │ u32_{1,2} │ ... │
│ ... │ ... │ ... │ ... │
│ u32_{31,0} │ u32_{31,1} │ u32_{31,2} │ ... │
└─────────────┴─────────────┴─────────────┴─────┘
在这种格式中,第 个 u32 的第 位位于索引 。这意味着读取第 个 u32 可以通过将每行循环旋转 个位置并提取第一列来完成。写入也可以用同样的方式完成,首先将第 列移动到索引 ,更新它,然后将其移回原始索引。
这种结构在加密下得以维持,除了列按 个一组进行批处理(GLWE degree):
┌───────────────────────────────────────────┬───────────────────────────────────────────────┬─────┐
│ GLWE([u32_{0,0}, ..., u32_{0,N-1}]) │ GLWE([u32_{0,N}, ..., u32_{0,2N-1}]) │ ... │
│ ... │ ... │ ... │
│ GLWE([u32_{31,0}, ..., u32_{31,N-1}]) │ GLWE([u32_{31,N}, ..., u32_{31,2N-1}]) │ ... │
└───────────────────────────────────────────┴───────────────────────────────────────────────┴─────┘
因此,访问第 个 u32 是通过首先同态地将列循环旋转 ,然后同态地将第一列循环旋转 。结果是,第 个 u32 的各位进入第一列每个 GLWE 的第一个系数,可以提取为一个 FheUint(见下文)。
u32 的 Ciphertext 格式
加密的 u32 值可以用两种不同的格式表示,取决于该值是用作数据还是控制。
| GLWE | FheUint | |||
| GGSW | FheUintPrepared |
FheUint — 数据表示(GLWE)
一个 32 位字被编码为单个 GLWE ciphertext:
其中索引函数 ,每个系数 对应 u32 的一位。
例如,将一个 u32 字打包到具有 个系数的 GLWE 中看起来像
[
1, 0, 9, 0, 17, 0, 25, 0,
2, 0, 10, 0, 18, 0, 26, 0,
3, 0, 11, 0, 19, 0, 27, 0,
4, 0, 12, 0, 20, 0, 28, 0,
5, 0, 13, 0, 21, 0, 29, 0,
6, 0, 14, 0, 22, 0, 30, 0,
7, 0, 15, 0, 23, 0, 31, 0,
8, 0, 16, 0, 24, 0, 32, 0
]
这种映射支持使用同态 partial trace 进行原生字节粒度的提取/拼接。partial trace 是 automorphisms 的组合,它将此矩阵的第一列置零。通过将 ciphertext 乘以 ,其他列也可以被置零。
FheUintPrepared — 控制表示(GGSWs)
用作控制(在算术、分支、位提取、索引中...)的 32 位字被编码为 32 个 GGSW 密文:
这种格式用于二元决策电路的求值、CMUXes、CSWAPs、blind rotations 等,这些将在下面描述。
当 u32 在加载/存储/选择(GLWE)格式中需要用作控制(GGSW)时,Phantom 使用 circuit bootstrapping (CBT) 从 FheUint 表示切换到 FheUintPrepared 表示。
Circuit Bootstrapping (CBT)
CBT 将 GLWE 的加密位(即 FheUint)映射到一组 GGSW(即 FheUintPrepared),将加密位 转换为加密相同位的 GGSW ciphertext:
其中 表示 u32 消息。
然后 GGSW 被用于我们之前描述的 external product 运算。external product 特别用于构建两个重要的加密运算:
CMUX,它支持在两个 GLWE 之间进行同态选择,给定一个加密控制位 的 GGSW。 CSWAP,它支持在两个 GLWE 之间进行条件同态交换,给定一个加密控制位 的 GGSW。
Binary Decision Diagram (BDD) 电路
以下是两位加法器最高有效输出位(即第 2 个输出位)的 BDD:
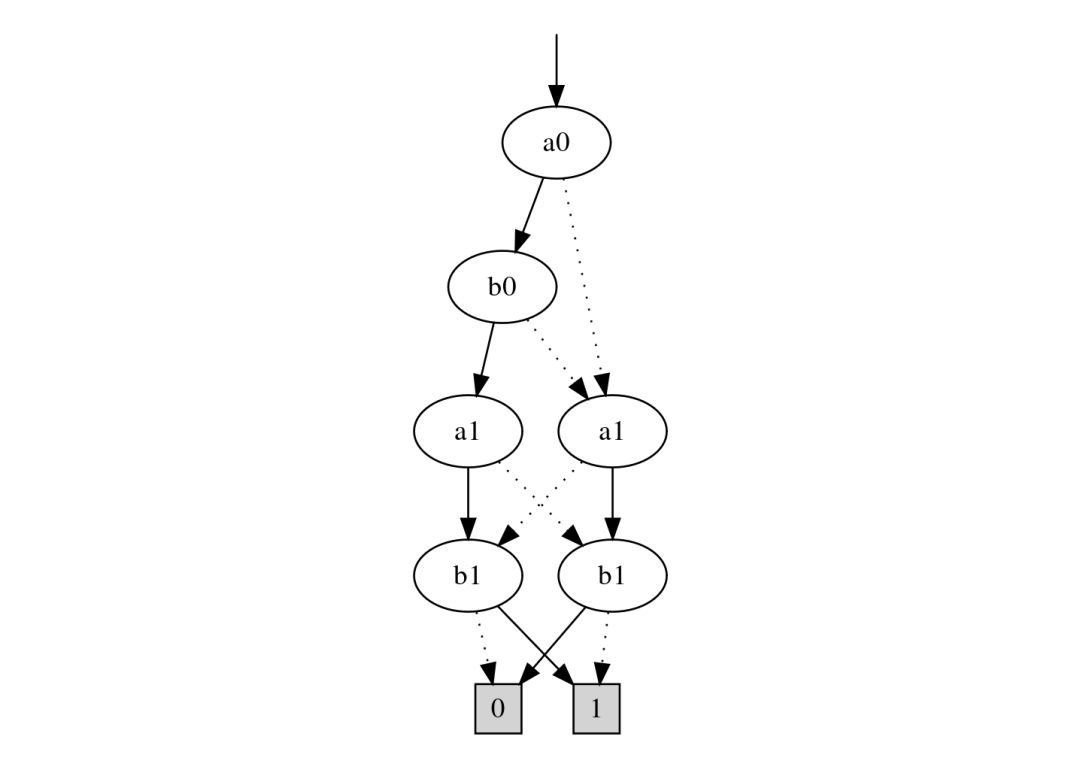
其中 a0, a1 是第一个输入的位,b0, b1 是第二个输入的位。
除了最后一层的节点外,所有节点都是输入节点。要求值 2 位加法电路,从上到下遍历 BDD。在每个节点,如果节点的位值为 0,则分支到用虚线箭头连接的子节点。否则分支到用实线箭头连接的子节点。遍历直到到达其中一个终端节点(在最后一层),即输出位。
现在如果两个输入(位 a0, a1, b0, b1)是加密的,如何遍历 BDD?从上到下的朴素方法会在每个节点使路径数量翻倍,因为两个分支都必须执行。这是行不通的。
但如果从下到上遍历 BDD 呢?确实,输出保持不变。但值得注意的是,我们避免了分支。相反,每个节点操作会折叠(即根据其值,节点选择其子节点之一),最多需要 K 次同态选择。
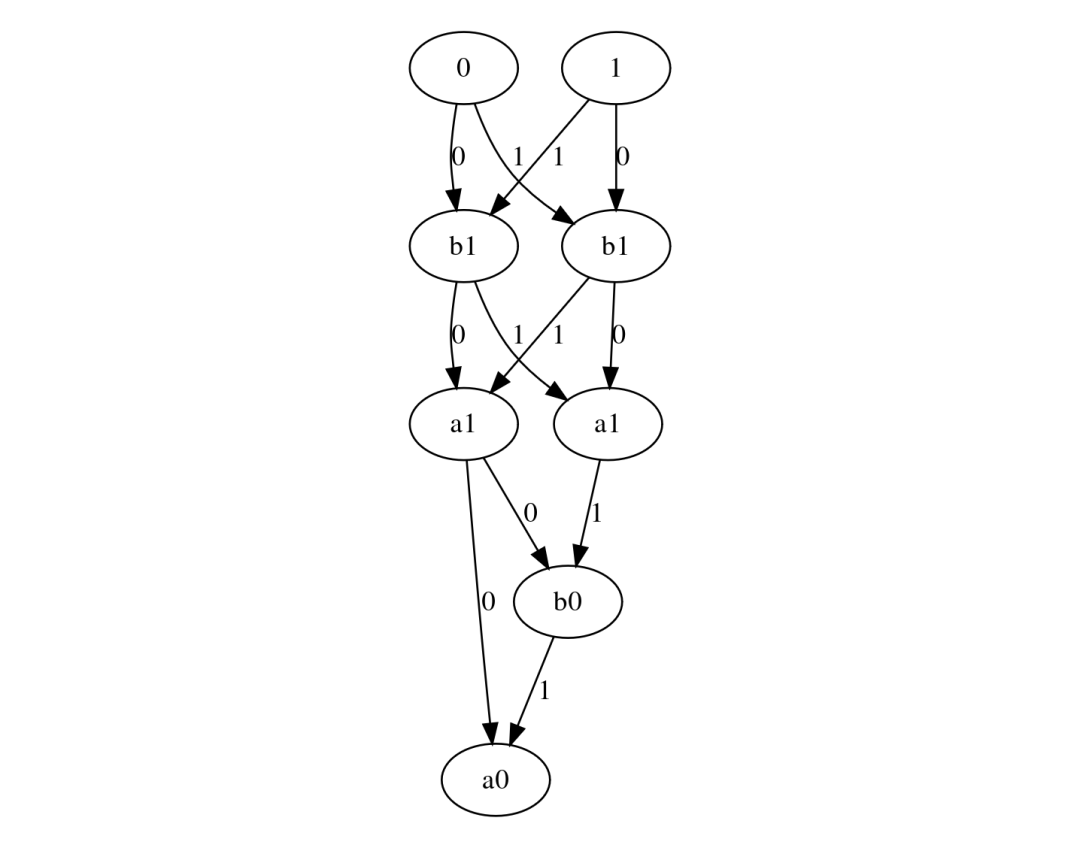
上图是 2 位加法器 BDD,但是反转的。从终端节点开始,我们迭代地折叠每个节点的入边(即如果节点的位值为 0 则选择标记为 0 的那个,否则选择标记为 1 的那个),直到最后一个节点(即 BDD 的根节点)。输出是最后一个节点选择的输出。我们将反转的 BDD 称为 BDD 电路。
当输入位 a0, a1, b0, b1 被加密时,每个选择都用 CMUX 实现:
其中 SELECT 在 b 等于 0 时选择 x0,否则选择 x1。
通常输入位以 GLWE ciphertext(FHEUint)的形式打包存储,而不是 GGSW 密文。要在加密输入上执行 BDD 电路,我们解包加密位并通过 circuit bootstrapping (CBT) 将每位转换为单独的 GGSW 密文(即 FHEUintPrepared)。
其中 表示 u32 消息。
所有算术/二元运算(如 add、sub、comparitors、and 等)的 32 位输入电路和 PC 更新都实现为 BDD 电路。电路的源代码可在此仓库获取。该代码为任意位宽(即字长 32、64、128、256 等)输入和 RISC-V 兼容的 PC 更新自动生成算术/二元电路。生成的电路与 poulpy FHE 库兼容。
https://github.com/phantomzone-org/arith-bdd
GGSW Blind Rotation(在 GLWE 内选择一位)
的 GGSW blind rotation 定义为:
其中指数 作为 FheUintPrepared加密:。
每个加密位 通过 CMUX 控制 的旋转:
将所有 个条件旋转链接起来,得到一个常数项为 的 GLWE。
GGSW Blind Retrieval
Blind retrieval 用于使用加密索引在加密数组中选择哪个 ciphertext 进行访问——而不泄露索引。
Phantom 支持两种变体:
Stateless blind retrieval (CMUX)
使用 FheUint32Prepared 索引位和 ,一个二叉 CMUX 树选择:
在 个折叠步骤中完成。输入数组保持不变。
由于我们有位级编码,我们通过 GGSW Blind Rotation 完成选择,将所需的位移动到检索到的 GLWE 的第一个系数中。
Stateful blind retrieval (CSWAP)
加密的 CSWAPs 重新排序 密文 直到:
与 stateless read 类似,GGSW Blind Rotation(也是可逆的)用于将所需的位移动到检索到的 GLWE 的第一个系数中。
在读取或覆盖之后,一个反向 CSWAP 序列恢复初始的加密顺序。
这支持在加密地址处进行加密内存写入。
GGSW Blind Selection(从 map / dictionary 中选择)
Blind retrieval 处理数组。Phantom 还支持在加密下从关联映射(hash maps)中进行加密选择,而不泄露访问的键。
给定:
一个 HashMap<u32, GLWE(value)>,一个加密索引 ,加密为 FheUintPrepared,
blind selection 返回:
如果索引 不在 map 中,返回 GLWE(0)。
求值者永远不会获知:
哪个条目匹配, 是否发生匹配(以及是否选择了回退值 GLWE(0))。
在内部,blind selection 使用 CMUX 来折叠 hashmap,直到只剩下索引 。
在加密内存中读写
使用 GGSW Blind Rotations 和 GGSW Blind Retrieval 以及一个作为地址的 FheUintPrepared,我们可以在加密内存上实现读和写操作。
回想一下,它被结构化为一个 32 x #u32 矩阵:
┌───────────────────────────────────────────┬───────────────────────────────────────────────┬─────┐
│ GLWE([u32_{0,0}, ..., u32_{0,N-1}]) │ GLWE([u32_{0,N}, ..., u32_{0,2N-1}]) │ ... │
│ ... │ ... │ ... │
│ GLWE([u32_{31,0}, ..., u32_{31,N-1}]) │ GLWE([u32_{31,N}, ..., u32_{31,2N-1}]) │ ... │
└───────────────────────────────────────────┴───────────────────────────────────────────────┴─────┘
**Read (stateless)**:当不需要写入或需要对同一内存进行多次读取时使用 stateless read。例如,当从 ROM 获取下一条指令或从 REGISTERS 获取 rs1、rs2和rd值时就是这种情况。stateless read 通过对矩阵的每一行(u32的每一位对应一行)调用 GLWE Stateless Blind Retrieval 来实现。**Read (stateful)**:当写入将在同一地址的读取之后进行时使用 stateful read。这是 RAM 的情况,load/store 发生在同一地址。它通过对矩阵的每一行调用 GLWE Stateful Blind Retrieval 来实现。这会置换 密文(和系数)以确保要读取的 u32的各位被移动到矩阵第一列的 GLWEs 的第一个系数中。Read (stateful) Rev:反向读取操作只能在 stateful read 之后调用,归结为在执行反向置换之前覆盖之前读取的位。 Write:写入调用将 stateful read 与其反向操作组合。
在每种情况下,检索到的加密单个位都被同态打包成单个 GLWE 以产生一个 FheUint。
构建块总结
u32 解释为数据 | FheUint |
u32 解释为控制 | FheUintPrepared |
FheUintFheUintPrepared | |
FheUint 内选择一位 | |
FheUint | |
FheUint |
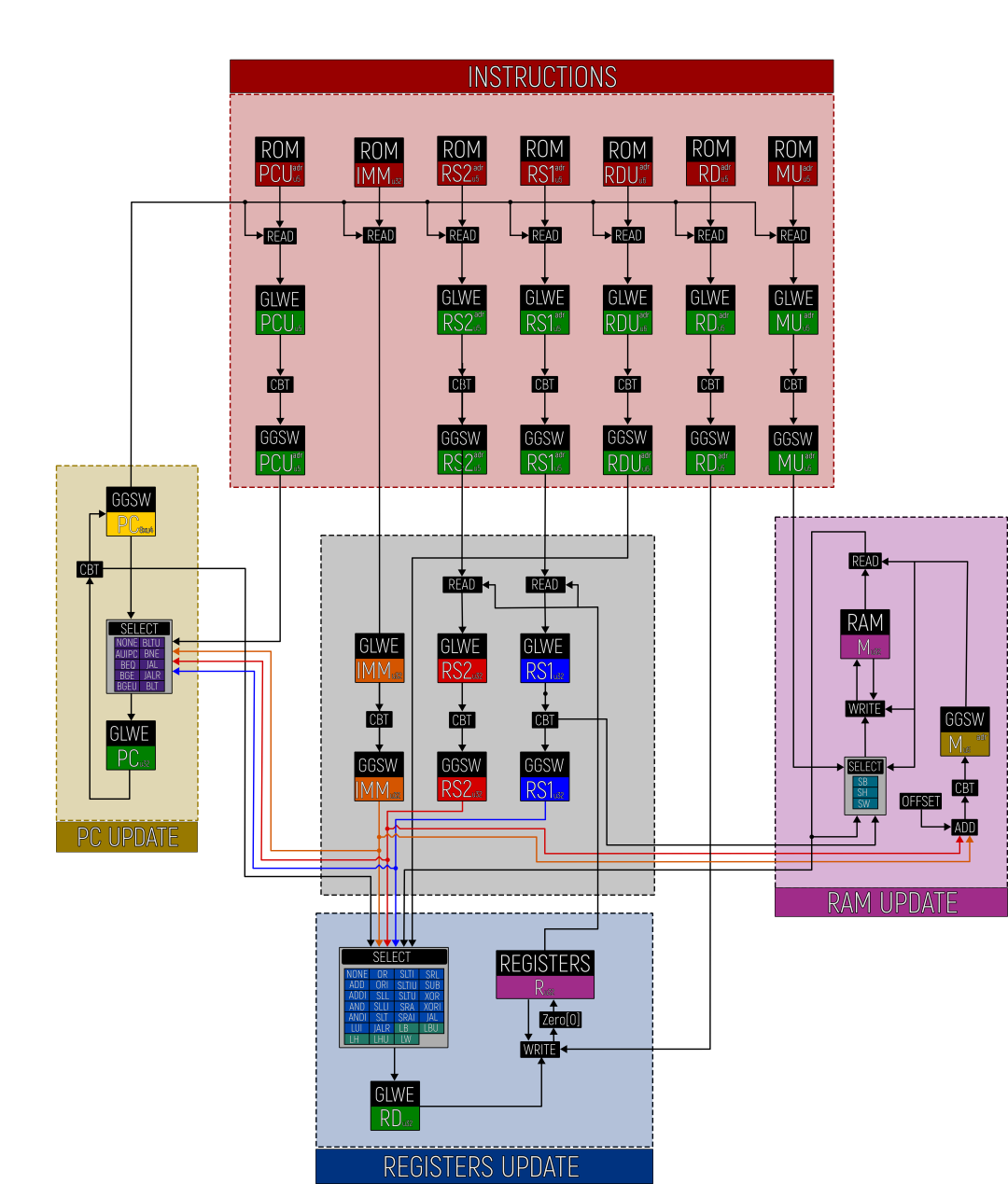
你将在下面找到一个详细的数据流图,说明加密 VM 的各个组件如何相互作用:
读取 ROM, 更新 RAM, 更新 REGISTERS, 更新 PC。
完整周期图
基准测试
基准测试使用 r6i.metal(32 核)获得。
ROM 和 RAM 大小分别为 0.4KB(9 位 PC)和 4KB(12 位地址)。
平均周期时间:655.711279ms
读取并准备指令组件(总计 128.46ms) Read:28.01ms 用于 ROM 上的 7x32 次 stateless reads。 Prepare:100.44ms 用于 circuit bootstrap 58 位(rs1: 5位,rs2: 5位,rd: 5位,imm: 32 位,rdu: 5 位,pcu: 4 位,mu: 2 位) 读取并准备 registers(总计 106.04ms) Read:7.52ms 用于 2x32 次 stateless reads。 Prepare:98.52ms 用于 circuit bootstrap 64 位。 读取 RAM:71.20ms 用于推导 12 位地址并执行 32 次 stateful reads。 更新 Registers:(总计 203.94ms) 求值 BDDs:133.08ms 用于求值 RV32I 的所有算术和加载操作。 Blind Select:1.54ms 用于选择正确的算术操作。 Write:69.31ms 用于 circuit bootstrap 32 位(噪声重置)并执行 32 次写入。 更新 RAM:总计 72.566678ms 用于 circuit bootstrap 32 位(噪声重置)并执行 32 次 stateful reverse reads。 更新 PC(总计 73.43ms) 求值 BDD:18.872475ms 用于求值所有分支操作并选择正确的操作。 Prepare:54.560689ms 用于 circuit bootstrap 9 位。
[^1]: 在硬件中,registers 位于处理器旁边(即实际操作发生的地方)。因此,从 registers 读取非常快。而 RAM 访问则慢几个数量级。
[^2]: 在 rv32i 中,所有指令除了 2 条外,要么只修改 Registers,要么只修改 PC,要么只修改 RAM。只有 JAL、JALR 同时修改 PC 和 Registers。