
STARK中的零知识
原文:https://hexens.io/blog/zk-in-starks
译者:Kurt Pan
STARKs 是当今密码学领域最令人兴奋的证明系统之一。其具有透明性、可扩展性、后量子安全性和深厚的数学基础。但 STARKs 的一个方面往往讲解不足,那就是零知识究竟是如何实现的。本篇博文将对此进行详细阐述。
我们将深入探讨在 STARKs 中实现零知识的优雅技术。你将了解到仅仅引入随机性是不够的,以及为什么 DEEP 组合多项式需要特别关注。
无论你是在构建 STARK 证明者,还是仅仅想了解其底层原理,本篇文章都旨在为你提供最清晰、最准确的零知识实践实现解析。
记号
在进入方案之前,定义一些常用的符号和参数:
—— 大小为 的有限域; —— 其乘法子群。 —— 次数为 的扩张域,。 —— 的循环子群,生成元为 ,。 —— 中一个循环子群的陪集,,且 。 —— 的消失多项式。
概览
STARKs(可扩展透明知识论证,Scalable Transparent ARguments of Knowledge)是一种密码学证明系统,允许证明者在不泄露计算内部细节或要求验证者重新执行该计算的情况下,使验证者确信某个计算已被正确执行。因其透明性(无需可信设定)和后量子安全性而备受青睐。
在核心层面,STARKs 将计算完整性归约为有限域上多项式的断言。证明者构造一个低阶多项式来编码计算的执行迹,使用 Merkle 树对其进行承诺,然后通过代数检查和交互式证明来验证其有效性。验证者只需检查少量的点值和相应的 Merkle 路径,便可高置信度地确认证明。
典型的 STARK 证明流程包括以下步骤:
迹生成 (Trace Generation)
在每个步骤对计算状态求值,并将结果记录在迹表中:多项式插值 (Polynomial Interpolation)
将迹表中的每一列表示为低阶多项式:商多项式 (The Quotient Polynomial)
使用多项式等式定义转移约束和边界约束。低阶扩展 (Low-Degree Extension, LDE)
将迹多项式和商多项式扩张到更大的求值域 ,以便进行概率性低阶测试:承诺 (Commitment)
将 LDE 结果通过 Merkle 树哈希生成简洁承诺:迹一致性检查 (Trace Consistency Check)
在原始域之外随机抽取点 ,求值:并检查:
其中 是对应约束域的消失多项式。
FRI 协议 (FRI Protocol)
证明 DEEP 组合多项式 的低阶性:其中
验证 (Verification)
验证者仅检查少量的求值点与对应的 Merkle 路径,即可确保证明的有效性。
添加零知识
可靠性确保证虚假断言以高概率被拒绝——但并不阻止验证者从证明者的迹中意外获取信息。为了实现完全的隐私,我们需要零知识:验证者除了知道计算已被正确执行外,不应了解任何内部计算细节。
在 STARKs 的背景下,这一点尤为微妙。尽管见证的任何部分都不会被直接泄露,但某些组件——例如在低阶扩展(LDE)域中的求值,或域外(DEEP)查询——都可能无意中泄露信息。
为此,现代 STARK 系统引入了两个独立的掩蔽层:
见证掩蔽 —— 在对迹多项式承诺之前,证明者为每一列迹多项式独立抽取一个随机低阶多项式并加到原多项式上。这些掩蔽在原始求值域 上恒为零,确保不影响约束满足。但在 之外——尤其是在用于 LDE 的更大求值域 上——它们充当有效噪声,隐藏真实值。 DEEP 组合多项式掩蔽 —— 即便见证已被掩蔽,约束系统仍可能通过 DEEP 组合多项式泄露信息。由于该多项式编码了在 上的求值,且验证者在随机点询问它,因此它也必须被掩蔽。证明者在最终的 DEEP 组合多项式上再加一个随机低阶多项式作为掩蔽。须确保证明此加性掩蔽仍满足可靠性和零知识所需的次数界限。
总结:仅仅引入随机性还不够——它必须是与证明系统代数结构精心对齐的结构化随机性。对迹多项式和 DEEP 组合多项式的双重掩蔽,是将一个可靠的 STARK 转化为零知识 STARK 的关键。
见证多项式的掩蔽
验证者以两种关键方式与迹多项式进行交互:在 FRI 阶段,它在求值域上测试它们的低阶结构;以及在迹一致性检查中,它在求值域之外的随机点对约束表达式进行求值。这两种方式都可能泄露执行迹的信息。
为实现零知识,我们对每个迹列多项式添加结构化随机性,以隐藏其在原始迹域之外的值,同时保留域内的正确性。具体做法是将随机低阶多项式与迹域的消失多项式相乘:
令
表示在域 上插值得到的第 个迹多项式,掩蔽后的版本定义为:
其中 是一次从 中均匀抽取的随机掩蔽多项式。
此掩蔽确保以下几点:
迹域内的正确性:对任意 ,有 ,因此
保证了所有转移和边界约束在迹域上仍然成立。
域外的随机性:对任意 ,因 ,故
若 均匀抽取,则 在 上是均匀随机的,从而确保在任何 的查询点,掩蔽后的迹不会泄露原始迹信息。
查询隐私:由于所有 FRI 求值和迹一致性检查均发生在 之外,每次对 的求值在统计上都与原始 相互独立,保护了见证不被泄露。
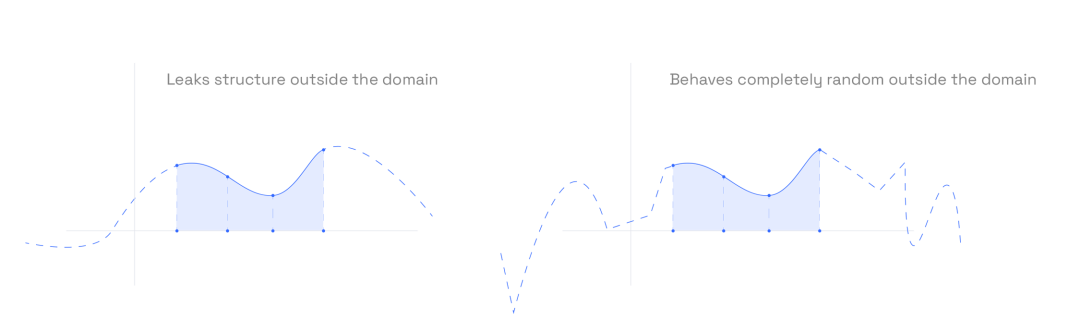
DEEP 组合多项式的掩蔽
即使在掩蔽了见证多项式之后,也不能保证零知识。问题出现在 FRI 协议阶段,在该阶段对 DEEP 组合多项式 进行低阶测试。在此过程中,验证者反复对 进行折叠,以降低其次数——而在每次折叠中,原始掩蔽多项式中的部分随机性也会被折叠并丢失。
关于拆分商多项式的说明
在应用 FRI 协议之前,必须将商多项式 转化为适合低阶测试的形式。具体来说,我们要求所有传递给 FRI 的多项式其次数都为 2 的幂,以便高效地递归折叠。
我们首先通过乘以适当的因子将 提升到下一个 2 的幂:
然后将 拆分为 部分,其中 是迹域的大小。这确保每个部分的次数严格小于 ,从而可以由 FRI 单独进行承诺和检查。
该分解表示为:
此结构允许验证者并行检查所有 ,使用单一的低阶协议(),并支持高效的 Merkle 树承诺与折叠。
拆分 为 个分量 后,证明者构造 DEEP 组合多项式 ,用于验证:
在 处与其声称值一致; 在 处与其声称值一致; 每个商分量 在 处与其声称值一致。
最终表达式为:
其中 是验证者选取的随机数,用于将证明者绑定到所有约束求值上。
该多项式 现接受 FRI 的低阶检验,其正确性意味着所有的 DEEP 查询——包括在迹部分和商部分——均得到了一致的回答。
为什么需要掩蔽 DEEP 组合多项式
即使每个迹多项式 已用 掩蔽,并且 DEEP 组合多项式 是从这些掩蔽后的迹多项式计算而来——这意味着 中的随机性已嵌入到 ——但 FRI 会递归地对 进行折叠,每次折叠都会使多项式次数减半。关键在于,每次折叠也会使嵌入的随机熵减半。经过多轮折叠后,剩余的随机性就很少,验证者可能开始观测到与底层见证相关的统计偏差。
为了防止这种信息泄露,我们需要在 FRI 协议开始前,直接向多项式中加入新的随机性。
通过掩蔽添加熵
令迹域大小 ,见证多项式的掩蔽次数为 。我们将最终的商 DEEP 组合多项式定义为:
其中
是一个均匀随机抽取、次数严格小于 的掩蔽多项式。
这一新加项 不会影响任何约束检查(因为 FRI 只验证低阶结构),但它可以确保即使经过多轮次数减半后, 的折叠求值仍在统计上与随机值无法区分。
选择掩蔽次数
的次数必须足够高,以确保即使经过多轮 FRI 和 迹一致性检查后,证明者的响应在统计上仍保持隐藏。
让我们仔细统计可能泄露的自由度总数:
迹一致性查询:在点 (次数为 的扩张域)处的每次检查都泄露 个 上的独立标量。这类查询的数量为 。 移位约束:对于每次查询,验证者同时对 和 进行求值,实际上将泄露翻倍,引入因子 2。 商多项式拆分与隐式查询:将 拆分为 个分量多项式 后,每次在 处的求值会泄露 在 这 个点的值信息,其中 是 次单位根群。因此,掩蔽预算必须随 缩放。 FRI-根商依赖:在 FRI 过程中,每轮操作于由大小为 的子群陪集构成的域上进行,这意味着对任意一个 在某个 FRI 点的求值,隐式依赖于 在 个位置的值。由于商值由迹的求值计算而来,且 FRI 在这些位置上递归折叠,迹掩蔽必须考虑 次求值:每个 FRI 查询点及其在 次单位根陪集上的 移位。 直接 FRI 抽查:FRI 还在其折叠表中执行 次抽查,这些通常与之前的查询不重合。因此,也必须独立掩蔽,额外增加 个自由度。
因此,为防止所有形式的泄露,掩蔽次数必须满足:
为什么这有效
引理:令先前定义的掩蔽迹多项式为
并假设我们将商多项式 拆分为 个分量:
令
为 DEEP 查询点集, 为 FRI 查询点集,
且
假设掩蔽次数 满足熵下界:
则所有查询值的联合分布:
在统计上与原始(未掩蔽的)见证多项式
无关。
换言之,即使验证者观测到所有 DEEP 查询及其 -移位,以及对商分量的 FRI 抽查,只要掩蔽次数足够大,也无法从中获知任何关于见证的额外信息。
小实例
为了将零知识 STARK 的抽象步骤具体化,我们通过一个在有限域上完全指定的小示例来演示。本示例将作为贯穿全篇的参考,用具体数值说明协议的各个部分。
我们在素域上进行计算:
乘法群 的阶为 96,且为循环群。令 为生成元。我们定义两个乘法子群:
迹域:,阶为 8, LDE 域:,阶为 16。
这与典型的 STARK 设置相对应:先在 上对执行迹进行插值,然后扩展到 以进行低阶测试和约束求值。
计算模型
我们模拟一个简单的计算:一个 8 步的斐波那契序列,递推定义为:
初始值为:
根据该递推关系,得到以下执行迹:
这些值表示计算过程中的内部状态。在 STARK 证明中,我们将这些值在迹域 上插值得到迹多项式,然后在低阶扩展 (LDE) 阶段将其扩展到更大的域 。
令 为次数小于 8 且满足:
的唯一多项式。对斐波那契值
进行插值,得到迹多项式:
该多项式完整地编码了在 上的执行迹,并将作为后续见证掩蔽和约束验证的起点。
掩蔽迹多项式
为了确保零知识,我们通过对迹域 的消失多项式加权来掩蔽迹多项式。这在 上保留所有原始值,但在其他点上将求值随机化。
令
为 上的消失多项式,并令
为一个随机掩蔽多项式。在本例中,我们选择:
其中掩蔽次数的选择依据如下:FRI 查询次数 ,DEEP 查询次数 ,商多项式拆分因子 。由此可计算
掩蔽后的迹多项式定义为:
将 的表达式代入,得到:
该多项式在所有 上的点与 完全一致,但在任何 (如用于迹一致性检查或 FRI 的点)处都表现为伪随机。
结论
零知识 STARK 基于两个互补的掩蔽:
见证掩蔽,隐藏了 之外的原始执行迹。 DEEP 组合多项式掩蔽,保护了在 FRI 中使用的多项式,确保熵不会耗尽。
两者结合,可使 STARK 证明仅泄露断言的真实性,同时保留透明性、可扩展性和后量子安全性。
致谢
本篇博文基于并受 2024 年 Ulrich Haböck 与 Al Kindi 所著技术报告 “A Note on Adding Zero-Knowledge to STARKs” 的启发。该文对见证掩蔽、商多项式分解以及小域 STARK 系统中的熵统计做了清晰且严谨的论述。本文中许多思想与形式化保证——尤其是关于 FRI、DEEP 查询及掩蔽多项式结构的部分——均直接借鉴或直观阐释了他们的成果。
https://eprint.iacr.org/2024/1037