A Succinct Story of Zero Knowledge
https://nibnalin.me/dust-nib/a-succinct-story-of-zero-knowledge.html
by Nalin Bhardwaj
We study the development of "production" zero-knowledge proofs starting from their theoretical roots in computational complexity theory and the PCP theorem, ultimately creating a summary of the most important developments in the study of zero-knowledge proofs.
If I had but the time and you had but the brain . . .
by Lewis Carroll, The Hunting of the Snark
Part1INTRODUCTION
Zero-knowledge proofs are extremely interesting primitives to study from a practical perspective. zk-SNARKs and zk-STARKs have captured a lot of attention from the blockchain/crypto space in recent years, going from theoretical research paper constructions to programmable privacy-preserving production circuits in just a few years. Starting with [Sasson et al. 2014]’s Zcash in 2014, over the past 5 years we’ve seen the advent of several decentralized blockchain applications that would be otherwise infeasible without ZK proofs. These include DarkForest: a completely decentralized strategy game using ZK proofs to create a "fog-of-war" [Dark Forest Team 2020] and MACI: a primitive for collusion resistant digital voting [Buterin 2019] among many others. Deeper than just the application layer, there have also been fundamental protocol-layer ideas such as the Mina protocol [Bonneau et al. 2020], StarkNet [StarkWare [n.d.]] and Cairo [Goldberg et al. 2021] from StarkWare, ZKSync [Gluchowski 2021], etc. that are blockchain scaling solutions using ZK SNARK/STARKs to securely scale transaction throughput in a decentralized ledger. Unsurprisingly, Ethereum creator Vitalik Buterin, too, expects "...ZK-SNARKs to be a significant revolution as they permeate the mainstream world over the next 10-20 years." [Buterin 2021]
On the theoretical counterpart, looking at the subject from the perspective of complexity theory, cryptographic zero-knowledge proofs that exist in production now are very much a consequence of a lot of early work in complexity theory, starting from Interactive Protocols (IP) leading up to the seminal PCP theorem, which directly translated into strategies for creating SNARGs, and further, led advances in the follow-up zero-knowledge SNARK/STARKs, the current state of the art in practical zero-knowledge proofs.
Part2INTERACTIVE PROOFS: IP
1Deterministic IP = NP
Informally, deterministic IP define the class of problems where a prover can convince a verifier of a witness, i.e. that the prover knows an input that satisfies a particular language in an (interactive) environment where they can communicate with each other.
Formally, let there exist a language and a pre-image . Let the prover and verifier have a transcript (a log of messages back and forth) . Then, an interactive proof system is given by a verification algorithm (run by the verifier) with the properties:
Completeness: True assertions have valid proofs. That is, if , then such that accepts. Soundness: False assertions have no proof. That is, if , then rejects. Efficiency: stops in time .
From the definition, it is clear that NP Deterministic IP, since with simply , for all languages in NP, can verify the witness in poly-time.
We can also show the other direction: Deterministic IP NP . Assume there exists Deterministic IP. Then, there exists a transcript between the prover and the verifier for some . Then, since we know that the verifier runs in poly-time, must also be poly-time. Further, since the verifier is deterministic, the prover can just simulate the verifier to generate the transcript between them, and with this transcript as witness, the verifier can verify the solution in poly-time. So, in totality, we have shown deterministic IP 's equivalence to NP. This characterisation of IP is so popular now that even NP is sometimes defined this way (c.f. [Sipser 1996]).
Given that deterministic IP is just NP, it's not immediately clear why we should care about it. What if we add randomness, allowing the verifier to be probabilistic? That is, letting the verifier produce false positives or true negatives with some small (practically negligible) probability. Formally, we let the prover encode the previously mentioned conditions of deterministic IP as follows:
Completeness: If , then the transcript is accepted with at least probability by . Soundness: If , then for all possible provers , the transcript is rejected with at least probability by . Efficiency: stops in time .
Intuitively, one might compare this probabilistic IP class with other complexity classes that use randomness. For instance, with BPP, the class of problems solvable in polynomial time by a probabilistic Turing Machine. For BPP, [Bennett and Gill 1981] proved that BPP P / poly and in fact, it is conjectured that P=BPP (for instance, in [Goldreich 2011]). Given this information about BPP, intuitively, one might guess that adding randomness to IP is not significantly helpful.
But, on the contrary, we will show that adding this randomness actually makes IP quite powerful.
2IP = PSPACE
Not only is the entire polynomial hierarchy PH contained in IP (as shown by [Lund et al. 1992]), but IP is PSPACE!
To that end, first, we show that . Let there exist a language and a verifier for it. We show that a prover can compute the maximum probability with which some element is accepted by the prover in , and therefore, .
Consider a decision tree of possibilities of the interactive protocol where each path of length from the root to the node corresponds to some prefix of a transcript . Since runs in polynomial time, the depth of the tree is at most polynomial, and each node has at most children since each message has at-most polynomial length. In this tree, let's define an auxiliary attribute : for each node is the maximum probability with which the prover can make the verifier accept a proof such that the prefix of the transcript corresponds to the path that ends at node , i.e. . We can compute this using dynamic programming on trees: For each leaf, we assign if accepts at that leaf or otherwise. For all internal nodes, let the set of children of a node . For an internal node where the next message is a response from the prover, we can set and otherwise to . Therefore, in this setup, is the maximum probability with which the prover can make the verifier accept the input, and since we can run this computation in , .
Now, we show by showing that a complete language is in . This was originally proven by [Shamir 1992], but here we demonstrate a simpler proof presented in [Shen 1992].
We work with the complete language of totally quantified boolean formulae which consists of quantified formula of the form where is a and if is odd and if if even. (Note that we actually only require to be an alternating sequence of and , a symmetric proof if we switch the parity of the starting element.)
Arithmetization: We convert into an arithmetic polynomial using the following transformation:
Variable: Clause: Formula:
Clearly, the outputs of the polynomial are equivalent to that of the formula on binary inputs and .
Next, we note that if we fix values , then . evaluates 1 if and only if is true. Similarly, if was , we note that . evaluates to 1 iff is true. With these observations, let be defined as and let be defined as . Then, we can rewrite the original quantified boolean formula is true iff
Based on this, we describe a naive protocol:
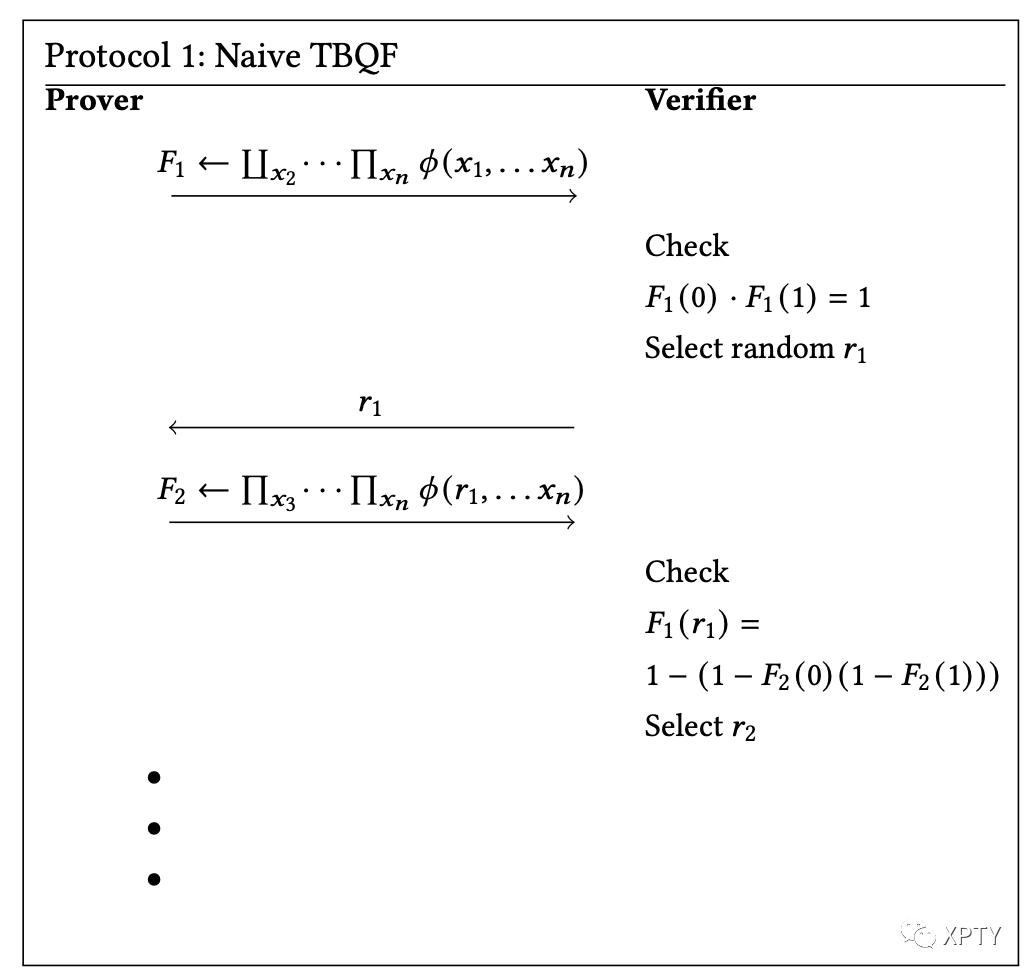
Immediately, it's clear that the protocol is not efficient: The degree of each polynomial is . This follows from the observation that for , the degree doubles with each .
To address this issue, we observe that in equation (1), each . But this implies, for any . So by reducing the power of any intermediate polynomials to 1 , we obtain a simplified representation of equation (1) of the form:
where is the reduced degree polynomial corresponding to the variable . Notice that for all the reduced except the innermost , the degree of the intermediate polynomials is at most 2 , and for the innermost , the degree is upper bounded at .
With this clever trick, we can create a modified version of the Naive protocol that successfully proves : At the th step in the protocol, we prove the th polynomial in our equation. If it is of the form of a or , we proceed similarly to the Naive protocol. Otherwise, if it's of the form (for some ), we simply check if , with the variables and being analogous to the Naive protocol as well.
We now show that this satisfies all conditions to be a IP protocol:
Completeness:, if the prover is not cheating, they can simply compute the polynomial with the randomness and send it back to the verifier and the equations will hold for any future values of randomness . Soundness: By the Schwartz-Zippel lemma, the probability that the verifier's check holds true but the polynomials are not actually equal is , where is the degree of the polynomial and is the size of the prime field we're working in. We now compute a strict upper bound for : For each operator or , there is error , error for the last operators, and error for all operators in the form of Overall, we have error , which is clearly sufficient to obtain negligible error with the size of the field being . Efficiency: Efficiency follows since all polynomials have length , and therefore any comparisons, multiplications etc. can be computed symbolically in time.
This finishes our proof that is, indeed, extremely powerful. Essentially, we have derived a protocol for by transforming a boolean formula into a polynomial. The key idea, then, is to "strip" each polynomial in the equation, randomly fixing a variable in the polynomial and checking if previous answers agree with the answers in the future.
3Arthur-Merlin Games
We now look at an interesting variant of the class, : Arthur-Merlin games. This is a restricted class of in which the verifier cannot use "private" randomness, i.e. a verifier's messages are simply completely random messages in some distribution.
. It is trivially seen that since it's simply an additional restriction on any language in . But, in fact, IP. While we won't formally prove this, we present an intuitive explanation of this: Notice that in the proof for , we described a protocol that is already in (since all verifier messages are random). This is a clear indication that is at least as powerful as , but in fact, since is an "upper bound" for (and consequently ), and thus .
Arthur-Merlin Games are a precursor to SNARGs in that they show us that, in theory, powerful zero-knowledge proofs can exist in a decentralised environment like a public blockchain, where all computational intermediates are readable by an adversary prover/verifier. Using an protocol allows the prover and verifier to leave their internals public, and they can safely use public randomness oracles (for instance, recent blockchain block hashes or randomness from a prior trusted setup).
Part3ZERO KNOWLEDGE
While interactive protocols (and Arthur Merlin Games) are extremely interesting as standalone constructs, we now turn our focus to protocols that possess the "zero-knowledge" property. Informally, a zero-knowledge proof is a proof that does not allow the verifier to learn anything other than the fact that a particular assertion is being proven true.
More formally, we define a zero-knowledge proof system as one where there exists some probabilistic poly-time, non-interactive algorithm (called the simulator) which, when given any verifier and any pre-image , produces output that is indistinguishable from the verifier’s point of view of the interaction with the prover. Therefore, the zero-knowledge property in an interactive proof allows a prover to not leak any unnecessary information about its pre-image while proving the assertion securely via the witness. Thus, zero-knowledge is a security property([noa 2021]), and just like other security properties, there are two variants of zero-knowledge:
Computational security: This type of security relies on the hardness of computational problems (for instance, problems in NP). These rely on the idea that it is computationally infeasible for the verifier to brute-force and find a pre-image that corresponds to a particular witness/transcript. Statistical security: Such security relies on the idea that the distribution of the witness/transcript generated for an arbitrary pre-image is statistically "close" to that of any other pre-images, virtually making it indistinguishable from those pre-images for the verifier. This notion of proximity is formalised by the notion of negligible function([noa 2020]): the distance function between the witnesses/transcripts in the domain of pre-images is a negligible function.
Next, we present a classic example of statistical zero-knowledge proofs to show a flavour of the ideas underlying practical constructions of such proof systems:
4Graph 3-coloring
A 3-coloring of an undirected graph is an assignment (say "Red," "Green," and "Blue" colors) such that no pair of adjacent vertices are assigned the same colour. We show that there exists a statistical zero-knowledge proof system for the language of graphs that are 3-colorable.
Assume there exists a one-way function that both the verifier and prover initially agree on using. Then we describe a protocol as follows:
Prover: Say, the prover has a 3-coloring it wants to prove. Let be a permutation of selected uniformly at random, and let . Then, for all , let boxes Send the boxes to the Verifier. Verifier: Choose a random edge , and send it to the prover. Prover: Send and to the verifier, essentially unboxing and . Verifier: Check that and are distinct, and that the prover's commitments match the claimed pre-images, i.e. and Reject if not.
We now prove that this is a zero-knowledge interactive protocol:
Completeness: Note that if is a valid 3-coloring, then is a valid 3-coloring as well for any . Thus, if is a valid 3-colouring, the verifier definitely accepts.
Soundness: If is not a valid coloring, then there must exist some edge such that , so the verifier must reject with probability at least . If we simply repeat this protocol times, the probability that the verifier accepts an invalid coloring is .
Efficiency: Efficiency follows from a similar argument as Soundness, and thus details are omitted for brevity.
Zero-Knowledge: Now, we look at the most interesting property of this protocol. Intuitively, let's consider what the verifier learns in the course of the protocol: Since is established via a one-way function, the only information the verifier learns is and for some . But then, , i.e. it is simply an independent, random permutation of the complete colouring - all the information learnt is something the verifier could have simulated on its own. More substantially, we notice that this information learnt by the verifier is, in fact, something "close" to the information the verifier would have learnt for all other possible colourings (including invalid ones), implying that the protocol does indeed satisfy the statistical zero-knowledge condition.
And now, for the big reveal, we note that standard complexity theory results tell us that graph 3-colouring is an -complete language! This means that we have just shown that if one-way functions exist, all languages in have zero-knowledge proof systems. This is quite powerful, and a more general result follows:
If one-way functions exist, then every language in NP has both a computational zero-knowledge proof system and a statistical zero-knowledge argument system.
We skip the counterpart proof for computational zero-knowledge proof systems since the statistical zero-knowledge argument system already provides a strong intuition for the ideas used in demonstrating both kinds of zero-knowledge proof security.
Later, it turned out that even the assumption that one-way functions exist is extraneous. [Ben-Or et al. 1988] first proved this result by defining a new multi-prover model for interactive proofs. While their original application for this model was only to derive a proof free of the one-way function requirement, it turned out that their model for interactive proofs was significantly more powerful than even they originally expected. Let’s see how.
Part4MULTIPROVER INTERACTIVE PROOFS: MIP
is a variant of defined by [Ben-Or et al. 1988] where instead of just one prover, two independent provers initialise on some common input but are unable to communicate with each other after starting communication with the verifier, essentially allowing the verifier to cross-check any assertions between the two provers. [Ben-Or et al. 1988] were able to show that with this variant, the intractability assumptions of one-way functions were unnecessary to prove the existence of zero-knowledge proofs for all languages in .
In fact, as [Babai et al. 1991] later show, is as powerful, if not more, than just , i.e. the class of problems solvable by nondeterministic Turing Machines in exponential time.
While the relationship between and itself is not well known, certainly since standard results tell us . Note, however the strictness of both the results is unknown ( vs. and vs. ).
Another consequential result (that may be seen as a weak precursor to the theorem) was , i.e. a system with polynomially many rounds can be converted into one with a constant number of rounds and further, a system with any constant number of provers can be converted to one with 2 provers. This is quite a powerful result since it implies all generalisations, at least on the axes of provers and rounds collapse to . This was shown by [Lapidot and Shamir 1997].
While on one hand, as with , complexity theory saw progress by loosening constraints and defining new generalisations of the original protocol, on the other end of the spectrum, progress was made by considering restrictions on , such as with the theorem.
Part5PCP: SUCCINCTNESS AND THE HARDNESS OF APPROXIMATION
A probabilistically checkable proof is a type of proof that can be checked by a randomized algorithm using a bounded amount of randomness and reading a bounded number of bits of the proof. Much like randomised , a verifier is an algorithm that accepts correct proofs and rejects incorrect ones with high probability. While there is no obvious connection between s and interactivity, most research into started from the point of view of interactivity, and protocols like and randomised algorithms were at the intersection of complexity theory and cryptography at the time.
5PCP theorem:
Formally, the PCP Theorem states that ], where the first part refers to the number of bits of randomness required and the second part refers to the bits of proof the verifier algorithm needs to read. In English, this means that for any language in , it is possible to generate a proof such that to verify it with high probability, a verifier only needs to generate logarithmic bits of randomness and only needs to read a constant number of bits in the order of the length of the proof.
The theorem has been one of the crowning achievements of complexity theory. Consequences of the theorem not only had a strong impact on cryptographers' quest for succinct zero-knowledge proofs but also complexity theory more widely since they provided very strong bounds for approximating languages in general.
It is hard to overstate the seeming impossibility of this result. In some metaphysical sense, it means that we can write math proofs millions or billions of pages long that only need a small amount of computation for anyone else to verify. Unsurprisingly, this theorem was the culmination of a series of clever ideas and observations over the span of many papers, authors and years of hard work.
6Simpler results
As a warm-up, we take a quick look at how the framing of relates to the usual complexity theoretical classes.
coRP poly .
This follows from the definition of : it is the set of languages for which there exists a probabilistic Turing Machine that runs in polynomial time, is allowed to generate randomness, and correctly detects false instances and detects correct instances with high probability.
, poly .
This, too, follows from the definition of , when framed in the manner we did in previous section.
In the first part of the equality, since the machine can only read a logarithmic order of bits, these bits can be brute-forced by a polynomial-time TM anyway. Similarly, the latter part follows since a polynomial-time TM can try all possible strings of randomness of length in polynomial time, not requiring the randomness at all.
7
Finally, we now look at the ideas behind the core theorem and its consequences. This is meant to be an informal introduction to the core ideas of the proof, a formal reference can be found in [Arora et al. 1998] and [Dinur 2007].
Let us turn to our old example problem of graph 3-colouring. Since we know graph 3-colouring is an -complete problem, it is sufficient to come up with a scheme to solve it in to prove our assertion. So, let's look at our original solution. The verifier had to make queries and generate random bits, so clearly that solution is in
How can we improve it? It seems like we need to make queries because the prover could have found some colouring that is almost a 3-colouring, with maybe a couple faulty edges (like the graph below).
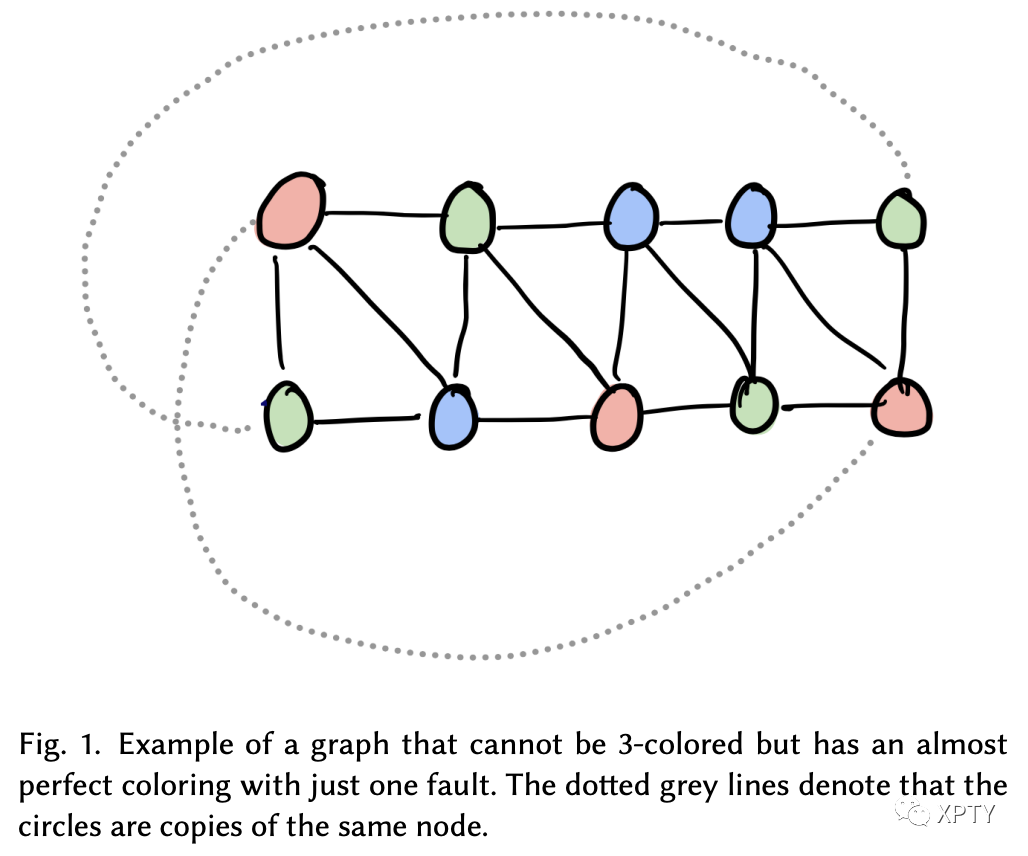
The only way to gain confidence about discovering such faults is to query almost all edges. The core implication of the theorem is that there is a way to amplify such errors, to a point where we only need to make a constant number of queries to detect any such errors with high probability. Essentially, we want to find a transformation from any graph into another graph such that if fails to have a 3-colouring, fails to have a 3-colouring badly.
Formally, we will find a way to transform any graph to a new graph such that if has a 3 -colouring, has a 3 -colouring, but if has no 3-colouring, i.e. for any 3-colouring there exists at least one edge such that it does not satisfy the colouring constraint, in , for any 3-colouring, a significant fraction (say 10%) of the edges do not satisfy the colouring constraint. This fraction is called the "gap" between a correct 3-colouring and any other 3-colouring.
Let's skeletonize our variables. Let be a 3coloring of the nodes. Next, define for an edge . Finally, let for some 3-coloring . Further, let , i.e. is the fault rate of the least faulty 3-coloring of a graph .
Next, we claim that we can create a transformation such that . (Provided for some arbitrary large constant and is an expander graph.)
If we succeed in creating such a general transformation, we can double the fault rate repeatedly to obtain a graph with a "high" fault rate. There are multiple ways to create such a transformation. The original paper ([Arora and Safra 1998], [Arora et al. 1998]) used special error-correcting codes, whose roots lie in the field of coding theory. At this point, the connection between the problem we're solving and coding theory should be somewhat intuitive, but due to the complexity of this solution, we do not study it here. Instead, we turn to a newer, more understandable solution by [Dinur 2007] based on ideas of gap amplification with expander graphs. Here, we present some intuition for the core ideas of [Dinur 2007]'s proof:
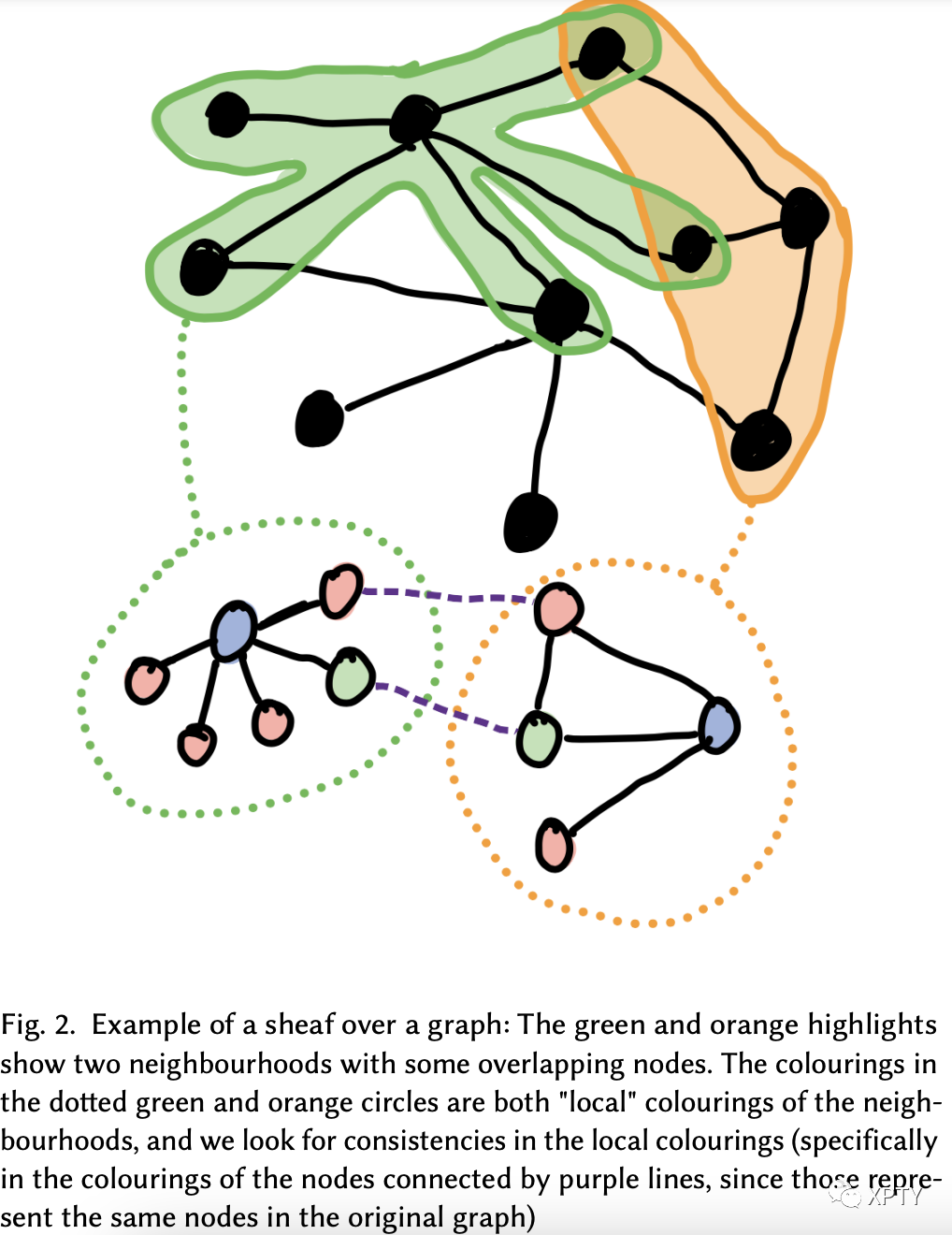
Step 0: Preprocess. As a first step, we take any graph and embed it in a larger expander graph such that for some constant . There are multiple simple ideas to accomplish this, so we omit too much detail. One example method for a constant-degree graph would be to take the union of edges in and some other constant degree expander graph with the same set of vertices. Step 1: Inhale. Let . Define . and for some constant . Further, for each node , let be the set of "local" colouring of and its neighbourhood : i.e. a colouring of just the neighbourhood of the node . Informally, a "local" colouring of a node is some valid colouring of the subgraph of the node and its neighbours in the larger graph. Then, for each edge , we can check the consistency of the local colourings and . Two neighbouring local colourings are "consistent" if the colourings of the nodes in the intersection can be assigned in a manner consistent with each other. Similar to before, in this new graph and we have properties similar to the ones previously described, but on . Notably, we can prove that . An intuitive explanation of why this happens is based on the properties of expander graph. In essence, we've taken a sheaf over balls of radius in , and any faulty edge in this ball is propagated to balls around it. This way, we're "spreading" the errors in any individual edge to edges in the vicinity.
Step 2: Exhale. One critical mismatch between the properties of and the aforementioned definitions in , however, is that we don't naturally have a 3-colouring of that we can use to repeat the process of doubling . The solution to this problem is to use a weaker form of the theorem recursively to return to a 3-colouring. Without getting into the technical details, this is a "solved" problem by the use of PCP encoding in the form of a local replacement gadget. For instance, one method is based on Hadamard encoding/linearity testing ideas (see [Dinur 2007] theorem for more information).
In total, we've created a gap amplification algorithm that with each round of inhale and exhale spreads the faulty edges around the graph to obtain a new graph that has (for some constant ) vertices. We only need to perform this doubling a logarithmic number of times, so we’ve obtained a transformation to a new graph where we only need to run the protocol we started a constant number of times to be confident in the provers witness.
8Hardness of Approximation
We now make a quick note about the consequences of the theorem on the hardness of approximation. We know that finding a 3-colouring is a hard problem (unless ). But perhaps, let's consider the problem of finding a 3-colouring that's almost correct, say, it satisfies of the edges in the graph. Is this problem also hard?
Say we use the transformation described in the previous section to obtain a representation of any graph . If we have an algorithm to correctly color at least of the edges, we would have been able to use it on this transformed graph , and then, since we've obtained a colouring that fails for fewer edges than the previously described "gap", it must be that this colouring of corresponds to a colouring of that is perfect. But then, we would have an algorithm for perfectly 3-colouring any graph . So, even approximating colouring must be hard!
It is quite cool to see that a result that started from the study of vanilla interactive protocols has yielded us an extremely powerful complexity theory result at large: approximation is hard. Interestingly enough, this connection between and the hardness of approximation was made in [Feige et al. 1991] even before the actual theorem itself was proven.
Part6FROM PCP TO CRYPTOGRAPHIC PROOFS
Now that we know that in theory, it is possible to create efficient proofs that only require reading a few bits of the proof and only require a small amount of randomness, we consider how to construct an actual SNARG - a succinct non-interactive argument of knowledge that can accomplish this. Then, we'll use this foundation to build up SNARGs into SNARKs/STARKs that additionally achieve knowledge soundness.
9Succinctness: Kilian's Notarised Envelopes
The first attempt at productionising was made by [Kilian 1992] in his protocol based on the idea of "Notarised envelopes" powered by Merkle trees.
Essentially, Merkle trees allow a prover to commit to a long string (say ) and generate proofs that for some index in the string. Merkle trees depend on collision-resistant hashing and work by constructing a binary tree of commitments of subranges on top of the original string, much like the cumulation in classic data structures like segment trees or Fenwick trees.
Let's say a prover is trying to prove to a verifier that some input such that has a proof system.
Verifier sends a collision-resistant hash function , to be used by the prover for the Merkle tree construction. Prover uses the witness for to construct a PCP for the input . It then constructs a Merkle tree using at the leaves and sends the Merkle tree root hash back to the verifier. The verifier then samples randomness bits for the verification and sends them to the prover. The prover computes a set of indices, say to query in the proof based on the verifier's randomness and opens , generating Merkle path proofs for each of the indices, and sends them back to the verifier. The verifier passes if the openings for each of the indices are valid and if a verifier running with the generated randomness would have opened those exact indices.
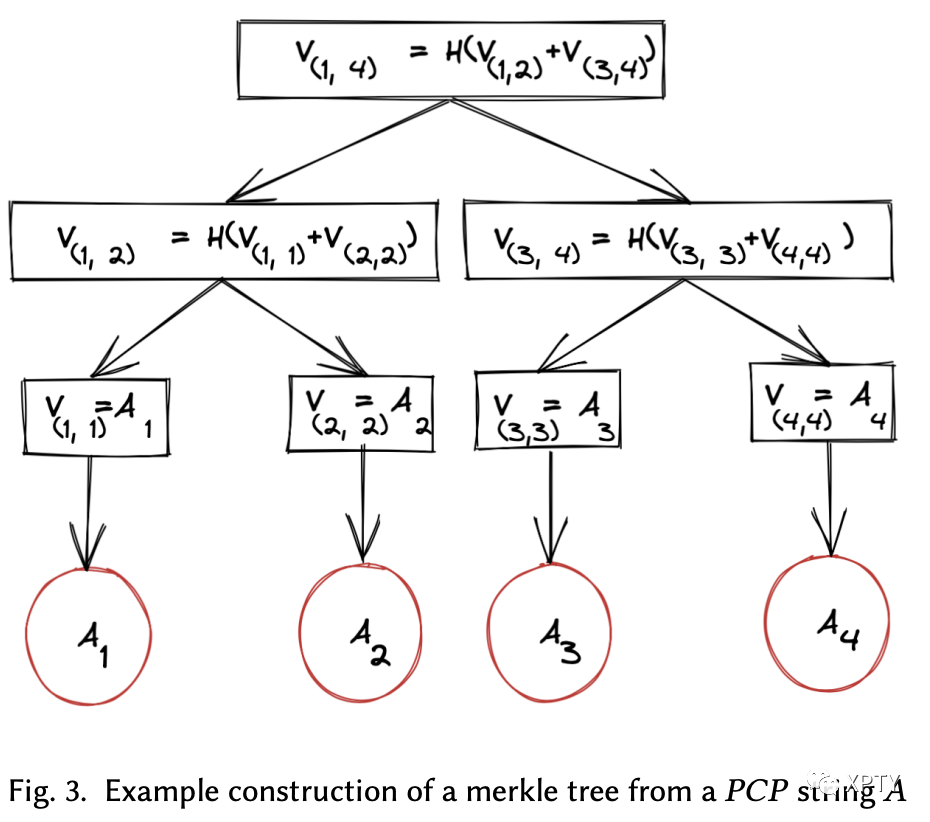
Clearly, this protocol is quite succinct! The verifier makes only a constant number of queries, and each query is answered with Merkle path proofs of logarithmic length of the PCP proof system.
Secondly, this protocol is sound. Since the prover commits the entire proof independent of the bits that are checked by the verifier, the soundness of this protocol is essentially equivalent to the soundness of the underlying proof system. Note that this protocol is a plain SNARG, so it does not attempt to be zero-knowledge.
Notice that this described protocol is not quite interactive. While Kilian's protocol is theoretically sufficient to obtain a succinct proof exploiting the locally checkable property of s, in practice, having the ability to perform multiple rounds in an interactive proof is quite useful (reasons for this are detailed in [Ben-Sasson et al. 2016]). With this motivation, [Ben-Sasson et al. 2016] described a very natural extension of [Kilian 1992]'s protocol that combines both aspects to create a hybrid construct: a PCIP. Like the moniker suggests, a is simply followed by an . Instead of simply sending and querying a single proof, the verifier is allowed to respond with random challenges after the first round, and each time the prover generates additional strings to convince the verifier more reliably.
10Non-interactive: Fiat-Shamir heuristic
Next, we look at a heuristic that takes any interactive proof and converts it into a non-interactive proof. Practically, non-interactivity unlocks several powerful use cases. On blockchains, for instance, this allows for a verifiable ledger for the proof since it's significantly easier to verify non-interactive proofs in a distributed system settings.
The original idea of the heuristic was presented in [Fiat and Shamir 1987] for a specific problem and easily generalised to any non-interactive public coin protocol. The primary idea of the heuristic is to use one random number and repeatedly hash it to obtain more randomness and replace the public coins in the original protocol with this new randomness.
To prove the security of such a transformation, the hash function is modelled in the Random Oracle Model (ROM) (from [Bellare and Rogaway 1993] and [Canetti et al. 2004]) as a truly random function. In practice, since such truly random hash functions do not exist, this model of security is somewhat weak and depends on the assumption that there exist "good enough" hash functions in practice that make any attacks infeasible.
With the power of the Fiat-Shamir heuristic in mind, we turn again to Kilian's protocol. Applying the collision-resistant hash function to the Merkle root hash of the string , we can obtain new randomness under the heuristic. So, we can just use this to generate the verifier's queries, converting the original four-round interactive protocol into a non-interactive one! The formalization of this non-interactive construction is credited to [Micali 1994].
11Zero-Knowledge Arguments: PIR + ECRH
Next, let's think about adapting Kilian's protocol to be zero-knowledge. To do so, we first define two primitives:
Private Information Retrieval: PIR
PIR is a protocol that allows a user to retrieve items from a server that possesses some database without revealing information about the item retrieved. For our purposes, it is sufficient to formalise a PIR protocol to consist of 3 algorithms:
which inputs some query, say , and returns an encrypted representation of it, say . which outputs an encrypted answer, say , to an encrypted database query which decrypts an encrypted answer into the constituent database items
If we assume we can create such algorithms succinctly and securely, a user can encrypt their query using , ask the server to generate an answer using and decrypt the answer using .
Extractable Collision-Resistant Hash: ECRH
ECRH is a collision-resistant hash function for which it is possible to algorithmically "extract" a pre-image for any output in the image of the function. That is, for an ECRH , given , we can find such that .
With these two primitives, we turn again to Kilian's protocol and consider how we can use them.
[Di Crescenzo and Lipmaa 2008] first discovered a use-case for PIR modifying Kilian's protocol. As a first message, the verifier may send a -encrypted encoding of the queries. Then, the prover can assemble a large database of every possible query a verifier could have made (along with Merkle path proofs that satisfy their committed root hash), and then use this database to -evaluate the verifier's queries and send them back. We can see why this modified protocol is sound: a prover essentially needs to be honest to be able to assemble valid answers to the PIR encrypted queries. Notice that even as a standalone, this method can be used to transform Kilian's interactive protocol into a non-interactive one without depending on the security of the Fiat-Shamir heuristic.
Next, we look at the [Bitansky et al. 2017] construction, which builds on [Di Crescenzo and Lipmaa 2008] in an extremely interesting way. Their primary idea is to use a protocol similar to [Di Crescenzo and Lipmaa 2008], but replace the in the Merkle tree construction with an . They also modify the [Di Crescenzo and Lipmaa 2008] protocol to -encrypt a verifiers random coins (instead of their actual queries), allowing verifiers to run offline independent of particular instances of a prover.
Essentially, ECRH's extractability allows their construction to take a root hash for a Merkle tree and extract it out all the way to the leaves, i.e. extract out an entire proof by just recursively applying the extraction algorithm for . Naively doing so, however, would incur an additional polynomial-time blowup with each level, so we can only extract times in practice. To deal with this, they modify the structure of the Merkle tree, making it so each internal node can have a polynomial number of children rather than just binary.
With this change, we can start to see how we can show Knowledge soundness for the protocol. To convince a verifier, the recursively extracted string must contain valid answers to the PCP queries specified in its PIR queries. If not, we can show by a reduction that we can find collisions within the hash function. In particular, a collision finder could simulate the -encryption and obtain two paths that map to the same root but must differ somewhere (as one is satisfying and the other is not), obtaining a collision.
Further, if the verifier extracts a set of arbitrary leaves that are satisfying with respect to the -encrypted queries, the same set of leaves must also be satisfying for almost all other possible queries and are thus sufficient for witness-extraction. Formally, we can see a contradiction as if this was not the case then one would be able to use the polynomial-size extraction circuit to break the security of the .
The [Bitansky et al. 2017] construction is quite clever overall. It achieves a communication complexity and a verifier time complexity that is polynomial in the security parameter, the size of the instance, and log of the time it takes to verify a valid witness for the instance, obtaining full succinctness!
12ZK-SNARKs
It is no surprise that the bolded letters of previous parts of this section spell out ZK-SNARKs — it is because they have together defined all the pieces necessary to create a fully working zk-SNARK!
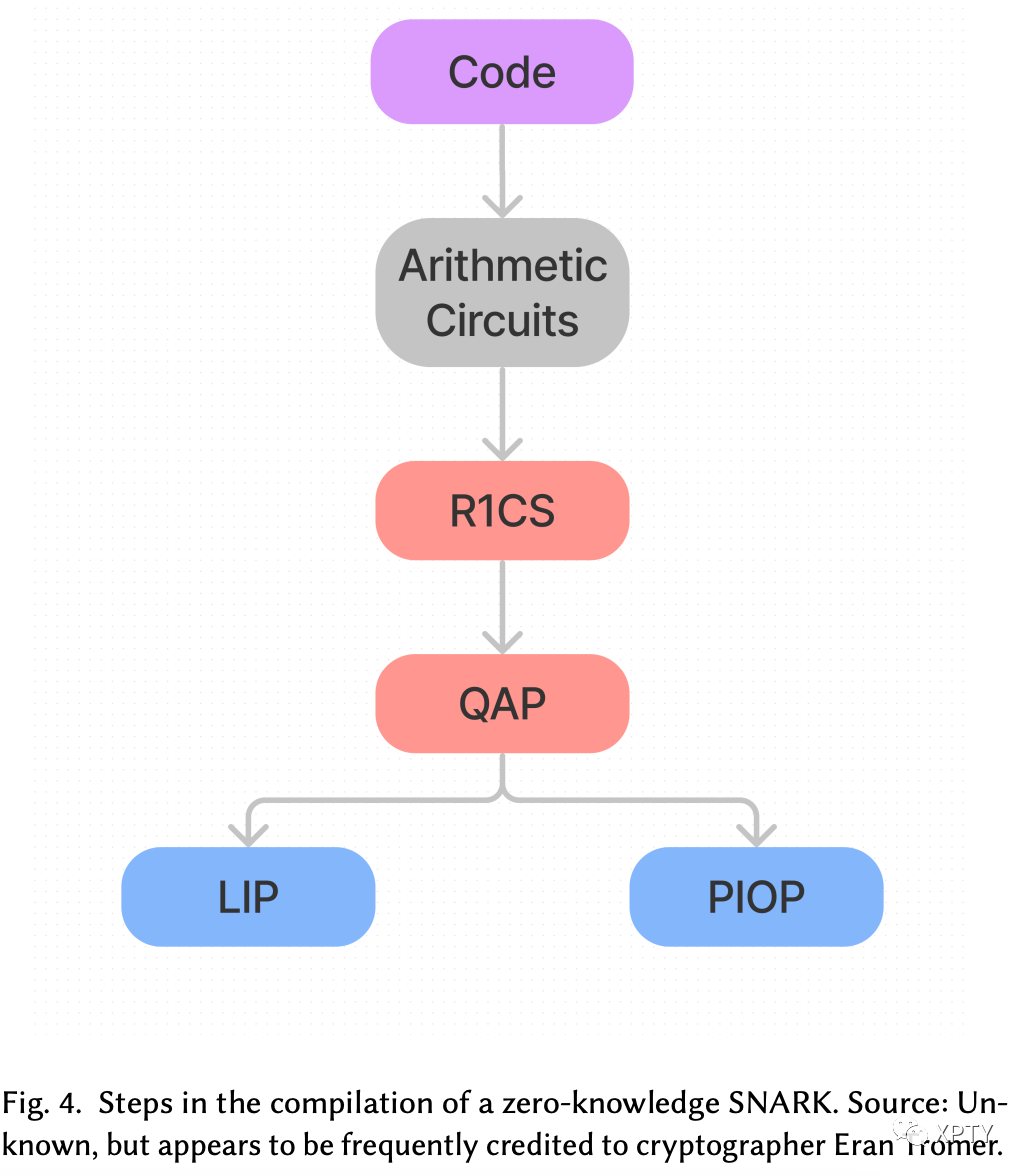
While this implementation of zk-SNARKs is not quite the state of the art, it is extremely close and was only put together in its entirety in 2014 (by preprints of [Bitansky et al. 2017]).
Having wade through this long journey between complexity theory and cryptography, we leave the reader with a stanza from Lewis Carroll’s The Hunting of the Snark:
For the Snark’s a peculiar creature, that won’t
Be caught in a commonplace way.
Do all that you know, and try all that you don’t:
Not a chance must be wasted today!
Part7STATE-OF-THE-ART SNARKS: FROM CODE TO PROOFS
At this level of understanding, while it should make sense that at least in theory, we can write succinct zero-knowledge proofs for any problems in NP, practically generating zero-knowledge proofs for arbitrary pieces of computation still feels like an opaque problem. So, we now turn to the state-of-the-art production zk-SNARK schemes. Many of these involve quite a few more interesting pieces that come together to create a much more "generalised" zk-SNARK. Given that these constructions involve a decent bit of math/cryptography, we’ll only focus on a high-level overview of how these schemes convert code to proofs:
13Code: Arithmetic Circuits
Of course, first, when we say "code", we need to define a formal encoding of this "code". We start with an arithmetic circuit representation of our computation: an arithmetic circuit consists of gates performing addition and multiplication, and wires that carry values in a field . Notice that the more common boolean circuits can be converted to arithmetic circuits using some simple algebraic manipulation.
Reasons for choosing this particular encoding will be clearer as we go forward, but for now, we note the from standard complexity theory the result that polynomial sized circuits are equivalent to polynomial-time Turing machines (up to a log factor) so, at the very least, circuits are powerful encodings for any computation we might want to do.
Practically, code for zk-SNARKs is most commonly written using the circuit language Circom, which was designed by iden3 particularly for this purpose. As one would expect from such novel technology, Circom is quite low-level and feels much like Verilog or other circuit simulating programming languages
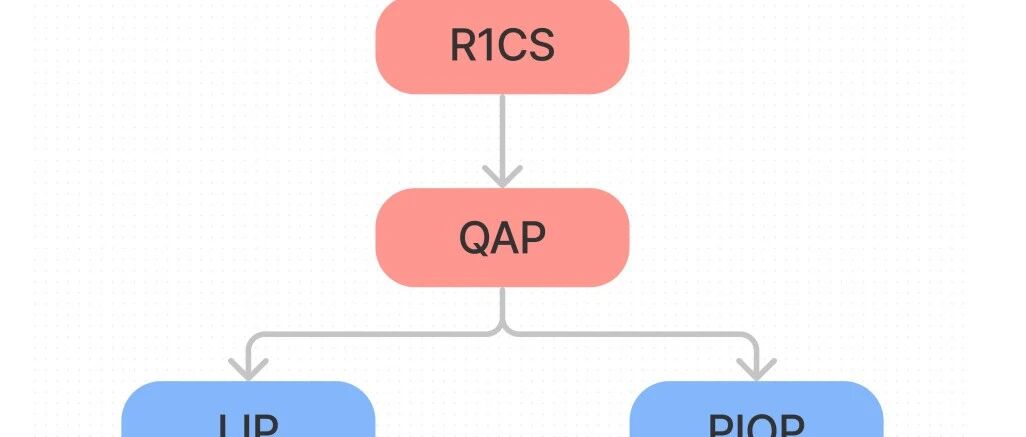
14Rank-1 Constraint System: R1CS
Next, we take our arithmetic circuit and convert it into an R1CS. An R1CS is a sequence of three vectors and a solution vector , where the equation , i.e. the product of the dot products of and with equals the dot product of with . You may convince yourself that we can transform any gates into constraints of this form with some simple algebraic manipulation on the inputs and outputs of a gate. By creating such constraints, we'll have a tuple of vectors. Each vector would have size equal to the total number of inputs to all the gates in the circuit, say , for future reference.
15Quadratic Arithmetic Programs: QAP
A QAP is pretty much just an R1CS that is represented as a polynomial. We’ve already seen some ideas to perform such a transformation, so we omit much detail, but simply note that this transformation uses Lagrange interpolation to go from groups of three vectors of length 𝑛 to 𝑛 groups of three degree-3 polynomials, where evaluating the polynomials at each 𝑥 coordinate represents one of the gates in the original circuit. Essentially, a QAP is the transformation of a large 𝑛 constraint R1CS to a single polynomial expressing all the constraints of the circuit, making any checks and further applications much more efficient.
16Linear Interactive Proof/Polynomial Interactive Oracle Proof
At this point, different constructions introduce different ideas for checking a QAP as a zero-knowledge proof. Omitting the mathematical details, every scheme finds a way to efficiently hide , while proving its existence to the verifier. There are two primary ways to achieve this:
Linear Interactive Proof (LIP) is an interactive proof where every message sent by a prover (including malicious ones) must be a linear function of the previous messages sent by the verifier. [Bitansky et al. 2013c] show a transformation from any PCP into a Linear PCP (a PCP where the "honest" function must be a linear function) and further, a transformation from a linear PCP into a two-message LIP, and then construct a SNARK from LIPs with low-degree verifiers. These are essentially generalisations of [Groth 2010] and [Gennaro et al. 2013] constructions. Polynomial Interactive Oracle Proof In a Polynomial Interactive Oracle Proof (PIOP), the prover sends low degree polynomials to the verifier, and rather than reading the entire list of coefficients, the verifier queries evaluations of these polynomials at random points, and combined with the Fiat-Shamir heuristic, this yields a zk-SNARK.
17Kate Commitments
While we have not gone into a lot of detail about proof construction, Kate commitments are the underlying cryptographic primitive that enables them. Even outside of the study of zk-SNARKs, polynomial commitments are highly ubiquitous, so we make a short note on the general construct of polynomial commitments.
Kate commitments, or KZG commitments, are a commitment scheme introduced by [Kate et al. 2010] that are extremely powerful constructs that allow a prover to commit a polynomial and show evaluations of that polynomial on any point with a single group element-sized proof in constant time. As such, Kate commitments and its variants lie at the heart of many PIOP-style zk-SNARK constructions (such as Marlin from [Chiesa et al. 2020a] and PLONK from [Gabizon et al. 2019]).
Part8OPEN QUESTIONS & FUTURE WORK
18Fiat-Shamir-Compatible Hash Functions
Earlier, we described the limitation of the Fiat-Shamir heuristic in that its security is so far only proven in the Random Oracle Model, which, of course, are somewhat shaky grounds to build on. It remains an open question whether there exist concrete hash functions that are compatible with the Fiat Shamir heuristic, i.e. if there exist hash functions that guarantee soundness for a transformed proof (and are also compatible with zero-knowledge proofs). There has been a lot of work on this topic, but there is still no known universal hash function that can be proven to be compatible without making strong, somewhat impractical, assumptions yet. On one hand, there has been research such as [Bitansky et al. 2013b] which shows that for three-round proofs, Fiat-Shamir transform using a concrete hash family cannot be proven to be sound via black-box reduction to standard hardness assumptions. On the other hand, recent work such as [Canetti et al. 2019] has shown constructions for a class of protocols whose security can be proven under assumptions stronger than the original hardness assumptions.
19Recursive ZK Proofs
Recursive zero-knowledge SNARKs are one of the most interesting use cases for zero-knowledge technology that are almost ready for practical use. As the name suggests, recursive ZK SNARKs unlock the ability to take a proof and verify it inside another proof, allowing for a lot more composability without blowing up proving/verifying times. Besides the real-world composability advantages, recursive zero-knowledge SNARKs are also of great interest because of their use case as a blockchain scaling solution, relying on the succinctness feature of SNARKs to compress secure verification of long blockchains. Mina Protocol ([Bonneau et al. 2020]) is currently implementing such an approach.
It should, however, come as no surprise that efficient recursive ZK SNARK constructions are quite hard to pull off. With the typical method of SNARK constructions that uses elliptic curve fields, the initial, hairy problem to solve is to find a pairing-friendly curve (see [Bitansky et al. 2013a]). Attempting to solve for this yields many interesting tradeoffs. Many of the options and possibilities have been explored in recent works such as Halo [Bowe et al. 2019], which uses elliptic curve cycles that do not require pairings and Fractal [Chiesa et al. 2020b], that eliminates the use of elliptic curves altogether. Overall, the study of efficient recursive ZK proofs is of great importance, and ripe territory for further exploration.
20Post-Quantum Zero-Knowledge
Many of the techniques described in previous sections depend on the computational hardness of certain problems, such as computing the discrete logarithm, which have been shown solvable by quantum computers in polynomial time by [Shor 1997]. Therefore, quantum computers may pose a significant threat to the security model and practicality of zk-SNARKs that use these techniques. There has been some work on making quantum attack resistant zk-SNARKs. For instance, [Gennaro et al. 2018] recently proposed a lattice-based zk-SNARK starting with SSP — square span programs (an alternative to the QAP intermediate for boolean circuits). Lattice problems are known to hold against quantum attacks [Ajtai 1996], so this is a very promising line of work.
21Optimisations
While this isn’t of much complexity theory interest, there has recently been a lot of work on improving the constant factor on verifying/constructing zk-SNARKs. Interestingly, besides just time, the practical use of SNARKs on blockchains such as Ethereum has motivated research aiming to optimise SNARK "gas" consumption. There is a monetary cost, called the gas cost, associated with each instruction executed in Ethereum smart contracts, so it is of significant practical utility to find ways to reduce the gas costs associated with verifying zero-knowledge proofs on blockchains. For instance, [Gabizon and Williamson 2021]’s FFLONK, a modification of the popular PLONK zk-SNARK scheme, was motivated by gas cost reduction. They discovered a modification to KZG commitments that allows for reducing the scalar multiplications necessary to verify the proof by nearly three times, albeit at the cost of almost tripling proof construction time. For reference, each scalar multiplication costs ∼ 6000 gas, or $4USD in Ethereum at the time of writing.